

{kind=link}
Speculative decoding is a way for dashing up massive language mannequin inference. A small, quick draft mannequin proposes a number of tokens. The big goal mannequin verifies them in parallel. If accepted, inference is quicker. If rejected, the system falls again gracefully.
EAGLE Crew, vLLM Crew, and TorchSpec Crew has launched the EAGLE sequence together with EAGLE 1, EAGLE 2, and EAGLE 3 has change into probably the most extensively adopted and virtually deployed households of speculative decoding algorithms throughout each analysis and manufacturing methods. Right now, that household will get a focused reliability improve with introduction of EAGLE 3.1.
What was Going Improper
Whereas speculative decoding performs properly in managed settings, efficiency typically degrades below completely different chat templates, long-context inputs, or out-of-distribution system prompts.
The EAGLE group traced this fragility to a phenomenon referred to as consideration drift as hypothesis depth will increase, the drafter progressively shifts consideration away from sink tokens and towards its personal generated tokens.
In easier phrases: the drafter is a small mannequin that predicts future tokens. As hypothesis will get deeper, it begins attending to its personal prior outputs as an alternative of the unique context. This degrades acceptance size and output stability.
Two underlying points had been recognized. First, the fused enter illustration turns into more and more imbalanced as higher-layer hidden states dominate the drafter enter. Second, hidden-state magnitude grows throughout hypothesis steps as a result of unnormalized residual path. Collectively, these results make the drafter progressively much less secure at deeper hypothesis depths.
Two Architectural Fixes in EAGLE 3.1
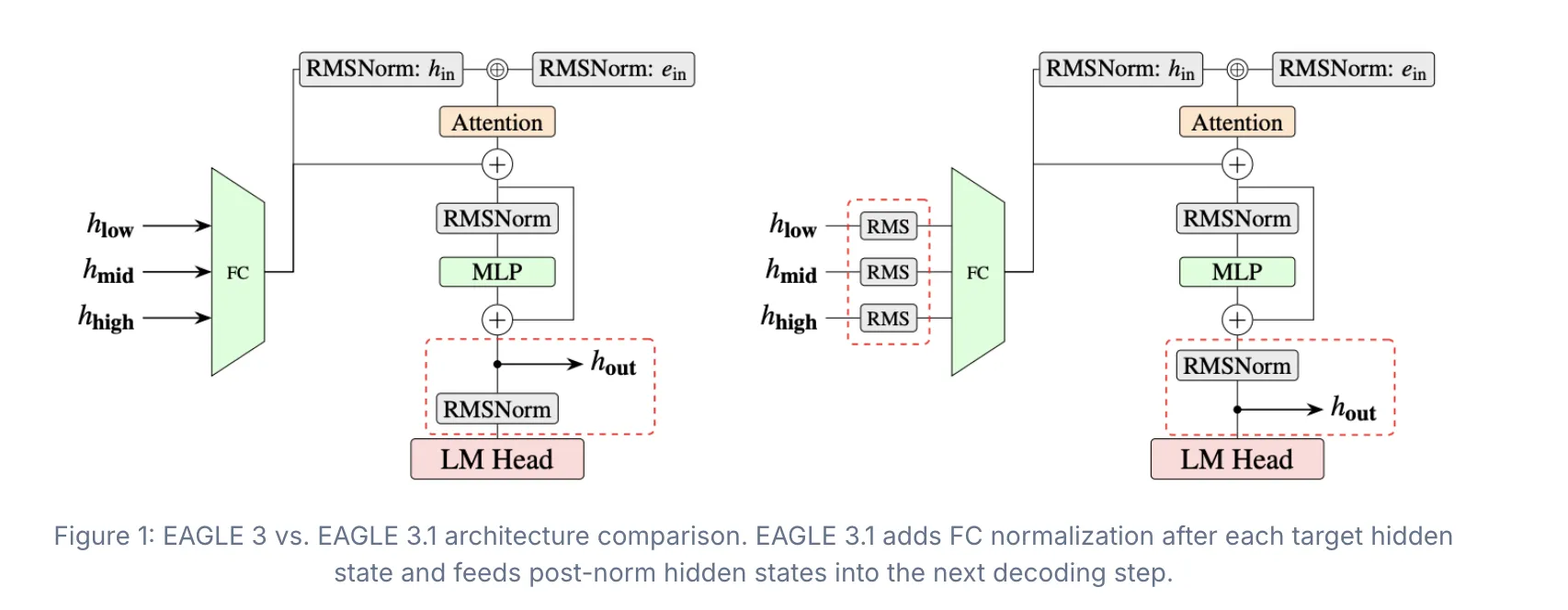
To handle consideration drift, EAGLE 3.1 comes with two key architectural enhancements: FC normalization after every goal hidden state and earlier than the FC layer, and feeding post-norm hidden states into the subsequent decoding step.
FC normalization stabilizes the hidden states that the drafter receives from the goal mannequin. With out it, hidden-state magnitude grows throughout steps, making the drafter more and more unreliable. Making use of normalization at every step retains the inputs bounded.
The post-norm design makes the strategy behave extra like recursively invoking the drafter throughout decoding steps, somewhat than merely appending further layers to the goal mannequin.
What These Fixes Ship
In contrast with EAGLE 3, EAGLE 3.1 demonstrates: higher training-time to inference-time extrapolation, stronger long-context robustness, larger resilience to speak template and system immediate variation, and extra secure acceptance size throughout various serving environments.
In long-context workloads, EAGLE 3.1 achieves as much as 2× longer acceptance size in contrast with EAGLE 3.
Coaching Infrastructure: TorchSpec
TorchSpec now supplies environment friendly coaching assist for EAGLE 3.1 and future speculative decoding algorithms. By decreasing coaching overhead and simplifying experimentation workflows, TorchSpec helps speed up iteration and exploration for next-generation speculative decoding analysis and deployment.
Based mostly on TorchSpec and vLLM, the analysis group additionally skilled and open-sourced an EAGLE 3.1 draft mannequin for Kimi K2.6, accessible on HuggingFace. The mannequin serves for instance of deploying EAGLE 3.1 with TorchSpec coaching and vLLM serving assist on a real-world serving mannequin
vLLM Integration: Config-Pushed and Backward-Appropriate
EAGLE 3.1 lands in vLLM as a config-driven extension of the prevailing EAGLE 3 implementation. The combination contains FC normalization assist, post-norm hidden-state suggestions, and elimination of hardcoded assumptions round goal hidden states.
Backward compatibility with present EAGLE 3 checkpoints is totally preserved. EAGLE 3.1 draft fashions will be plugged immediately by the identical speculative-decoding code path.
vllm serve nvidia/Kimi-K2.6-NVFP4
--trust-remote-code
--tensor-parallel-size 4
--tool-call-parser kimi_k2
--enable-auto-tool-choice
--reasoning-parser kimi_k2
--attention-backend tokenspeed_mla
--speculative-config '{"mannequin":"lightseekorg/kimi-k2.6-eagle3.1-mla","technique":"eagle3","num_speculative_tokens":3}'
--language-model-onlyBenchmark Outcomes on Kimi K2.6
The analysis group benchmarked the Kimi K2.6 EAGLE 3.1 draft mannequin on Kimi-K2.6-NVFP4 with vLLM (TP=4, GB200, non-disagg) on the SPEED-Bench coding dataset. EAGLE 3.1 delivers 2.03× larger per-user output throughput at concurrency 1. The speedup stays significant as concurrency scales: 1.71× at C=4 and 1.66× at C=16.
Marktechpost’s Visible Explainer
Key Takeaways
- EAGLE 3.1 fixes consideration drift — a newly recognized instability the place the drafter loses concentrate on sink tokens at deeper hypothesis depths.
- Two architectural modifications — FC normalization and post-norm hidden-state suggestions — stabilize the drafter throughout hypothesis steps.
- In long-context workloads, EAGLE 3.1 delivers as much as 2× longer acceptance size in contrast with EAGLE 3.
- Benchmarks on Kimi-K2.6-NVFP4 present 2.03× per-user output throughput at concurrency 1, dropping to 1.66× at C=16.
- EAGLE 3.1 is backward-compatible with EAGLE 3 checkpoints and is already merged into vLLM most important, transport in v0.22.0.
Take a look at the Technical particulars. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 150k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
Have to associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.