

{kind=link}
Translator Copilot is Unbabel’s new AI assistant constructed instantly into our CAT instrument. It leverages massive language fashions (LLMs) and Unbabel’s proprietary High quality Estimation (QE) expertise to behave as a wise second pair of eyes for each translation. From checking whether or not buyer directions are adopted to flagging potential errors in actual time, Translator Copilot strengthens the connection between prospects and translators, making certain translations should not solely correct however totally aligned with expectations.
Why We Constructed Translator Copilot
Translators at Unbabel obtain directions in two methods:
- Basic directions outlined on the workflow stage (e.g., formality or formatting preferences)
- Challenge-specific directions that apply to explicit recordsdata or content material (e.g., “Don’t translate model names”)
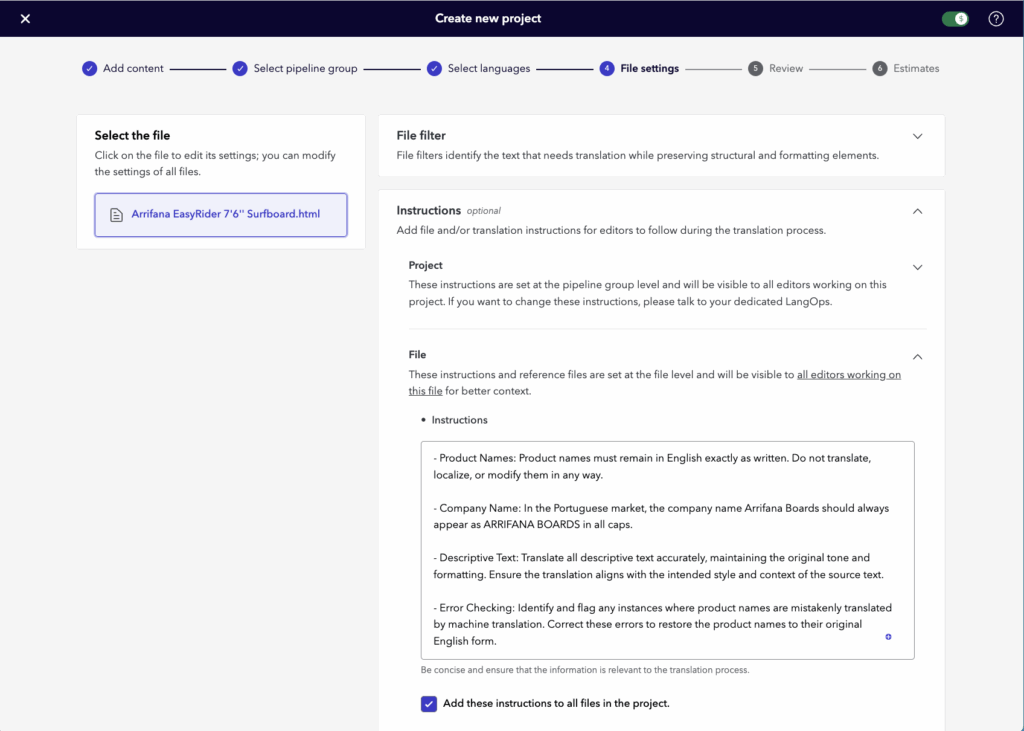
These seem within the CAT instrument and are important for sustaining accuracy and model consistency. However below tight deadlines or with complicated steering, it’s attainable for these directions to be missed.
That’s the place Translator Copilot is available in. It was created to shut that hole by offering computerized, real-time help. It checks compliance with directions and flags any points because the translator works. Along with instruction checks, it additionally highlights grammar points, omissions, or incorrect terminology, all as a part of a seamless workflow.
How Translator Copilot Helps
The characteristic is designed to ship worth in three core areas:
- Improved compliance: Reduces threat of missed directions
- Larger translation high quality: Flags potential points early
- Diminished value and rework: Minimizes the necessity for handbook revisions
Collectively, these advantages make Translator Copilot an important instrument for quality-conscious translation groups.
From Concept to Integration: How We Constructed It
We started in a managed playground setting, testing whether or not LLMs may reliably assess instruction compliance utilizing different prompts and fashions. As soon as we recognized the best-performing setup, we built-in it into Polyglot, our inside translator platform.
However figuring out a working setup was simply the beginning. We ran additional evaluations to know how the answer carried out inside the precise translator expertise, amassing suggestions and refining the characteristic earlier than full rollout.
From there, we introduced every thing collectively: LLM-based instruction checks and QE-powered error detection had been merged right into a single, unified expertise in our CAT instrument.
What Translators See
Translator Copilot analyzes every section and makes use of visible cues (small coloured dots) to point points. Clicking on a flagged section reveals two forms of suggestions:
- AI Strategies: LLM-powered compliance checks that spotlight deviations from buyer directions
- Potential Errors: Flagged by QE fashions, together with grammar points, mistranslations, or omissions
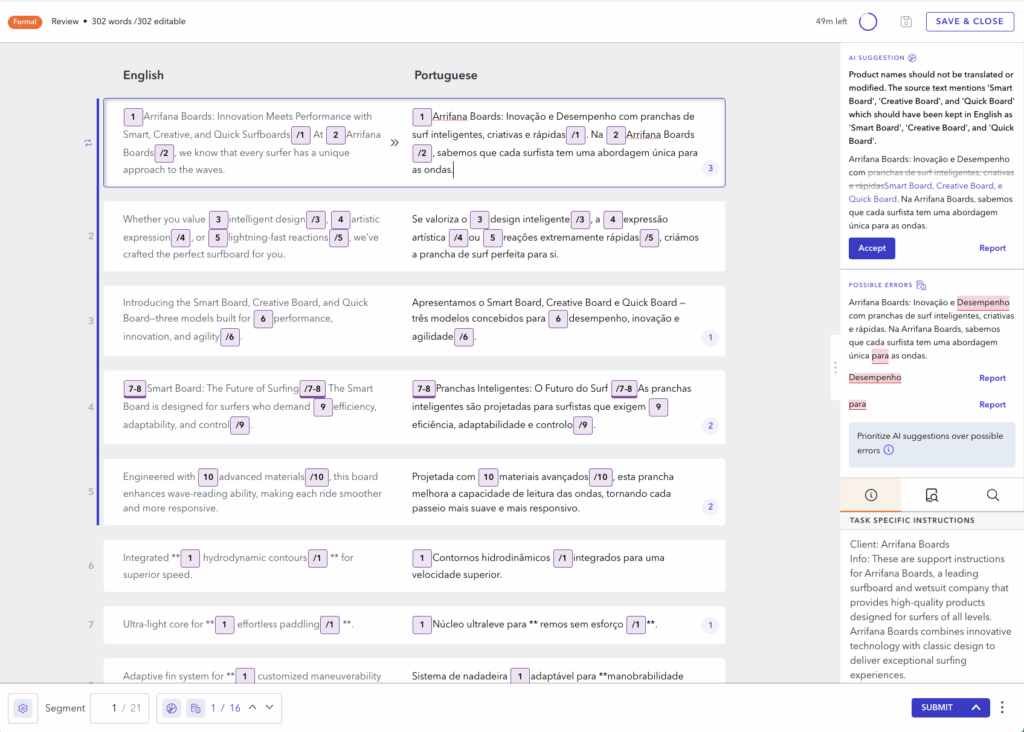
To help translator workflows and guarantee clean adoption, we added a number of usability options:
- One-click acceptance of recommendations
- Skill to report false positives or incorrect recommendations
- Fast navigation between flagged segments
- Finish-of-task suggestions assortment to collect person insights
The Technical Challenges We Solved
Bringing Translator Copilot to life concerned fixing a number of powerful challenges:
Low preliminary success price: In early exams, the LLM appropriately recognized instruction compliance solely 30% of the time. By means of in depth immediate engineering and supplier experimentation, we raised that to 78% earlier than full rollout.
HTML formatting: Translator directions are written in HTML for readability. However this launched a brand new problem, HTML degraded LLM efficiency. We resolved this by stripping HTML earlier than sending directions to the mannequin, which required cautious immediate design to protect that means and construction.
Glossary alignment: One other early problem was that some mannequin recommendations contradicted buyer glossaries. To repair this, we refined prompts to include glossary context, decreasing conflicts and boosting belief in AI recommendations.
How We Measure Success
To judge Translator Copilot’s influence, we carried out a number of metrics:
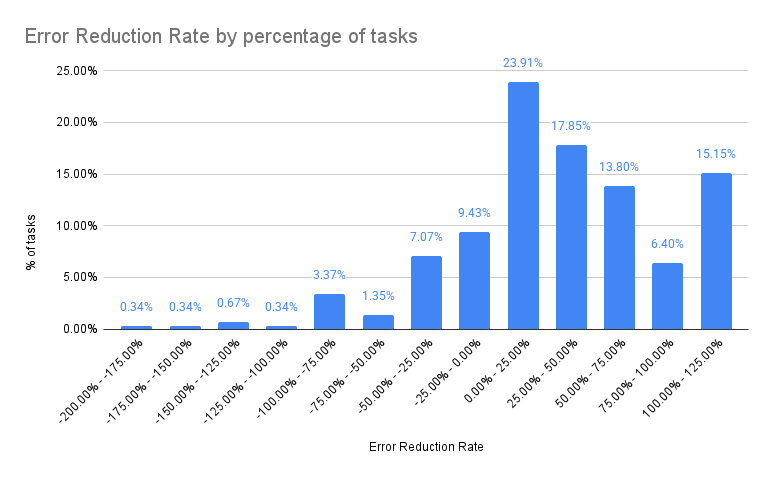
- Error delta: Evaluating the variety of points flagged firstly vs. the tip of every activity. A constructive error discount price signifies that the translators are utilizing Copilot to enhance high quality.
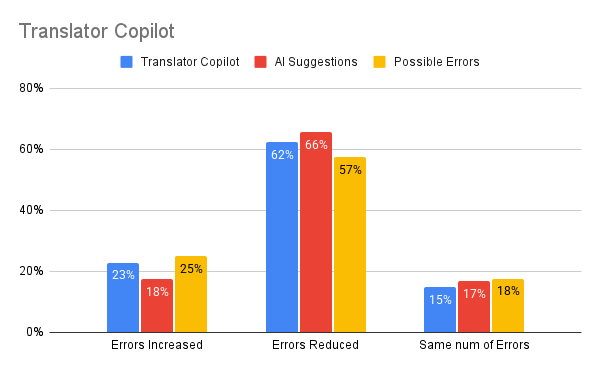
- AI recommendations versus Potential Errors: AI Strategies led to a 66% error discount price, versus 57% for Potential Errors alone.
- Consumer habits: In 60% of duties, the variety of flagged points decreased. In 15%, there was no change, doubtless instances the place recommendations had been ignored. We additionally monitor suggestion stories to enhance mannequin habits.
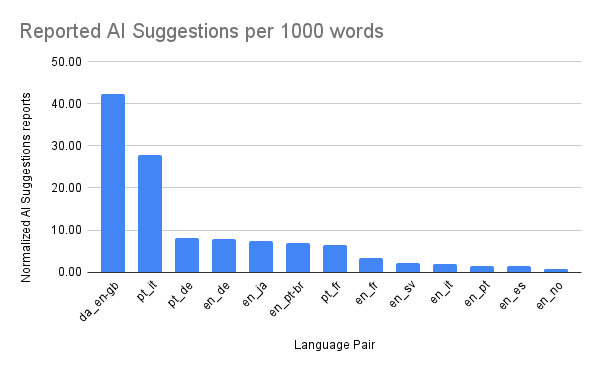
An fascinating perception emerged from our information: LLM efficiency varies by language pair. For instance, error reporting is increased in German-English, Portuguese-Italian and Portuguese-German, and decrease in english supply language pairs equivalent to English-Spanish or English-Norwegian, an space we’re persevering with to analyze.
Wanting Forward
Translator Copilot is a giant step ahead in combining GenAI and linguist workflows. It brings instruction compliance, error detection, and person suggestions into one cohesive expertise. Most significantly, it helps translators ship higher outcomes, sooner.
We’re excited by the early outcomes, and much more enthusiastic about what’s subsequent! That is just the start.