

{kind=link}
The discourse about to what degree AI-generated code needs to be reviewed usually feels very binary. Is vibe coding (i.e. letting AI generate code with out wanting on the code) good or dangerous? The reply is in fact neither, as a result of “it relies upon”.
So what does it rely on?
Once I’m utilizing AI for coding, I discover myself always making little danger assessments about whether or not to belief the AI, how a lot to belief it, and the way a lot work I have to put into the verification of the outcomes. And the extra expertise I get with utilizing AI, the extra honed and intuitive these assessments turn out to be.
Danger evaluation is usually a mix of three elements:
- Likelihood
- Impression
- Detectability
Reflecting on these 3 dimensions helps me determine if I ought to attain for AI or not, if I ought to evaluation the code or not, and at what degree of element I try this evaluation. This additionally helps me take into consideration mitigations I can put in place once I need to benefit from AI’s velocity, however cut back the chance of it doing the flawed factor.
1. Likelihood: How seemingly is AI to get issues flawed?
The next are a number of the elements that provide help to decide the likelihood dimension.
Know your instrument
The AI coding assistant is a operate of the mannequin used, the immediate orchestration taking place within the instrument, and the extent of integration the assistant has with the codebase and the event atmosphere. As builders, we don’t have all of the details about what’s going on underneath the hood, particularly after we’re utilizing a proprietary instrument. So the evaluation of the instrument high quality is a mix of realizing about its proclaimed options and our personal earlier expertise with it.
Is the use case AI-friendly?
Is the tech stack prevalent within the coaching information? What’s the complexity of the answer you need AI to create? How huge is the issue that AI is meant to unravel?
It’s also possible to extra usually take into account should you’re engaged on a use case that wants a excessive degree of “correctness”, or not. E.g., constructing a display screen precisely based mostly on a design, or drafting a tough prototype display screen.
Pay attention to the obtainable context
Likelihood isn’t solely concerning the mannequin and the instrument, it’s additionally concerning the obtainable context. The context is the immediate you present, plus all the opposite data the agent has entry to through instrument calls and so on.
-
Does the AI assistant have sufficient entry to your codebase to make determination? Is it seeing the information, the construction, the area logic? If not, the possibility that it’s going to generate one thing unhelpful goes up.
-
How efficient is your instrument’s code search technique? Some instruments index the complete codebase, some make on the fly
grep-like searches over the information, some construct a graph with the assistance of the AST (Summary Syntax Tree). It could actually assist to know what technique your instrument of alternative makes use of, although finally solely expertise with the instrument will let you know how properly that technique actually works. -
Is the codebase AI-friendly, i.e. is it structured in a manner that makes it simple for AI to work with? Is it modular, with clear boundaries and interfaces? Or is it an enormous ball of mud that fills up the context window shortly?
-
Is the present codebase setting instance? Or is it a large number of hacks and anti-patterns? If the latter, the possibility of AI producing extra of the identical goes up should you don’t explicitly inform it what the nice examples are.
2. Impression: If AI will get it flawed and also you don’t discover, what are the implications?
This consideration is principally concerning the use case. Are you engaged on a spike or manufacturing code? Are you on name for the service you’re engaged on? Is it enterprise essential, or simply inside tooling?
Some good sanity checks:
- Would you ship this should you have been on name tonight?
- Does this code have a excessive impression radius, e.g. is it utilized by quite a lot of different elements or customers?
3. Detectability: Will you discover when AI will get it flawed?
That is about suggestions loops. Do you may have good exams? Are you utilizing a typed language? Does your stack make failures apparent? Do you belief the instrument’s change monitoring and diffs?
It additionally comes all the way down to your personal familiarity with the codebase. If the tech stack and the use case properly, you’re extra prone to spot one thing fishy.
This dimension leans closely on conventional engineering expertise: check protection, system data, code evaluation practices. And it influences how assured you might be even when AI makes the change for you.
A mix of conventional and new expertise
You might need already seen that many of those evaluation questions require “conventional” engineering expertise, others

Combining the three: A sliding scale of evaluation effort
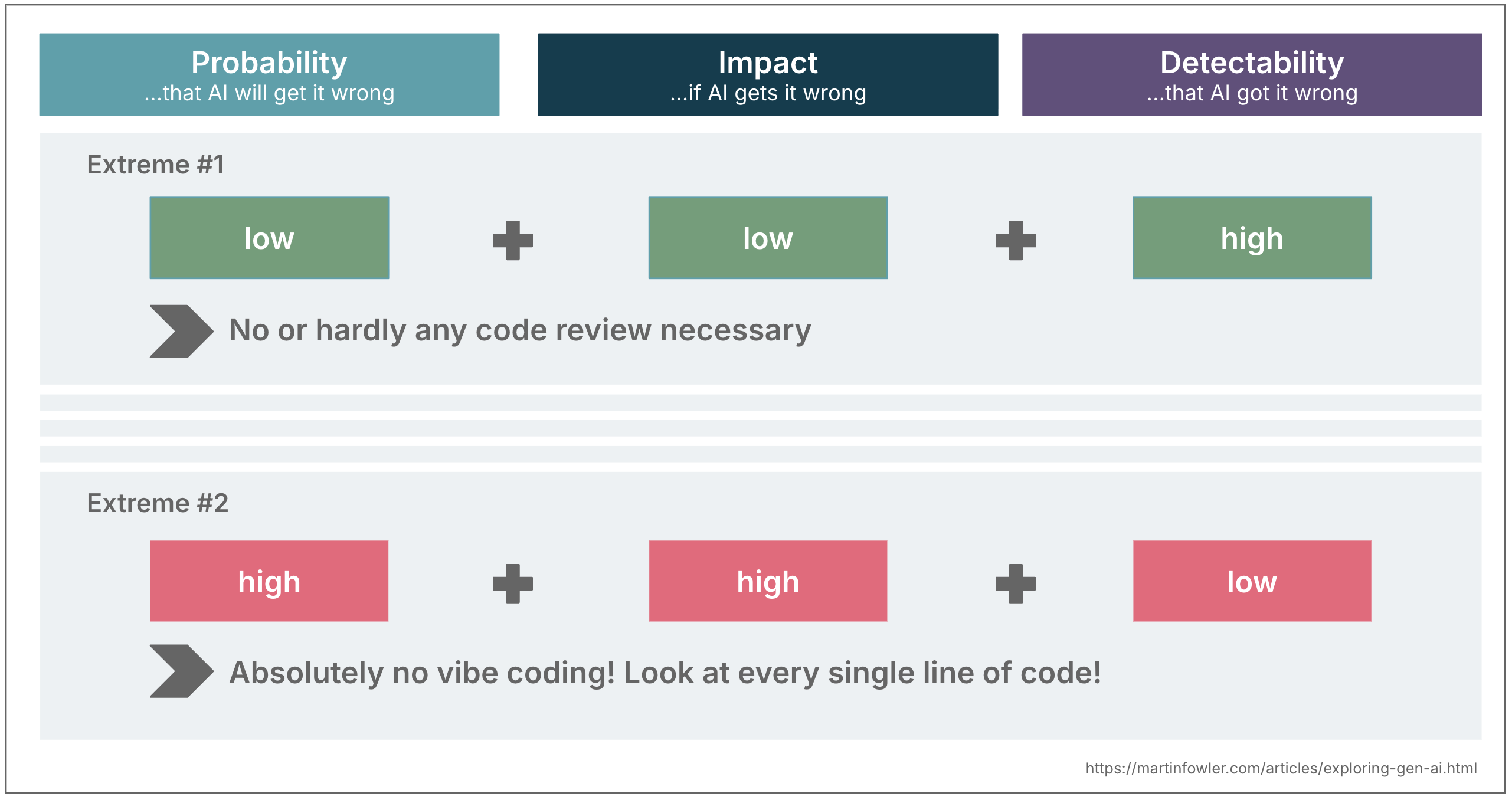
Once you mix these three dimensions, they will information your degree of oversight. Let’s take the extremes for instance as an instance this concept:
- Low likelihood + low impression + excessive detectability Vibe coding is okay! So long as issues work and I obtain my purpose, I don’t evaluation the code in any respect.
- Excessive likelihood + excessive impression + low detectability Excessive degree of evaluation is advisable. Assume the AI is perhaps flawed and canopy for it.
Most conditions land someplace in between in fact.
Instance: Legacy reverse engineering
We not too long ago labored on a legacy migration for a shopper the place step one was to create an in depth description of the present performance with AI’s assist.
-
Likelihood of getting flawed descriptions was medium:
-
Instrument: The mannequin we had to make use of usually did not comply with directions properly
-
Out there context: we didn’t have entry to the entire code, the backend code was unavailable.
-
Mitigations: We ran prompts a number of occasions to identify verify variance in outcomes, and we elevated our confidence degree by analysing the decompiled backend binary.
-
-
Impression of getting flawed descriptions was medium
-
Enterprise use case: On the one hand, the system was utilized by 1000’s of exterior enterprise companions of this group, so getting the rebuild flawed posed a enterprise danger to status and income.
-
Complexity: However, the complexity of the applying was comparatively low, so we anticipated it to be fairly simple to repair errors.
-
Deliberate mitigations: A staggered rollout of the brand new utility.
-
-
Detectability of getting the flawed descriptions was medium
-
Security internet: There was no present check suite that may very well be cross-checked
-
SME availability: We deliberate to usher in SMEs for evaluation, and to create a characteristic parity comparability exams.
-
With no structured evaluation like this, it might have been simple to under-review or over-review. As an alternative, we calibrated our strategy and deliberate for mitigations.
Closing thought
This sort of micro danger evaluation turns into second nature. The extra you employ AI, the extra you construct instinct for these questions. You begin to really feel which modifications might be trusted and which want nearer inspection.
The purpose is to not sluggish your self down with checklists, however to develop intuitive habits that provide help to navigate the road between leveraging AI’s capabilities whereas lowering the chance of its downsides.