

{kind=link}
Picture by Writer
# Introduction
For the previous two years, the AI business has been locked in a race to construct ever-larger language fashions. GPT-4, Claude, Gemini: every promising to be the singular answer to each AI drawback. However whereas firms competed to create the most important mind, a quiet revolution was taking place in manufacturing environments. Builders stopped asking “which mannequin is finest?” and began asking “how do I make a number of fashions work collectively?”
This shift marks the rise of AI orchestration, and it is altering how we construct clever functions.
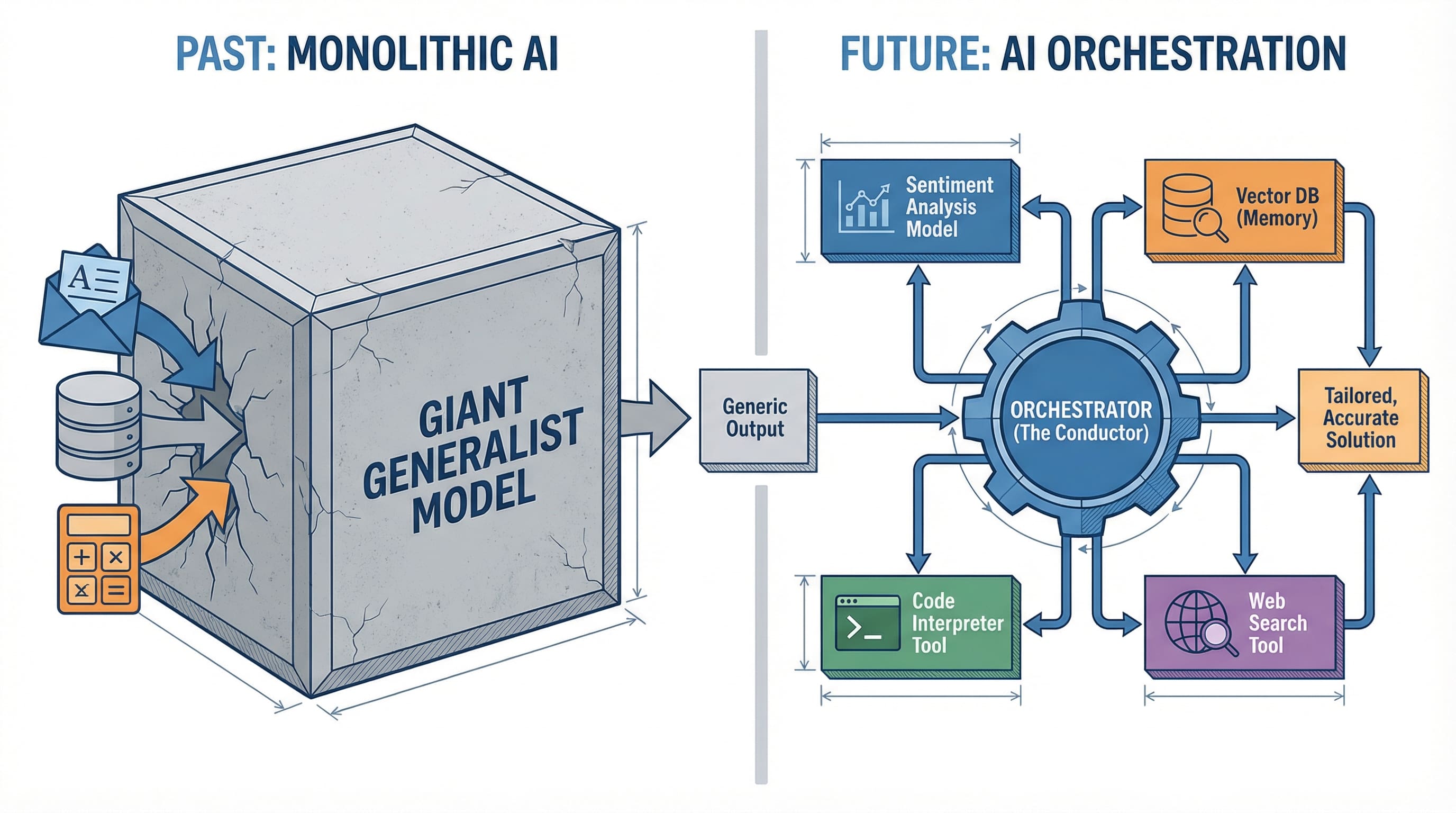
# Why One AI Cannot Rule Them All
The dream of a single, omnipotent AI mannequin is interesting. One API name, one response, one invoice. However actuality has confirmed extra advanced.
Contemplate a customer support utility. You want sentiment evaluation to gauge buyer emotion, data retrieval to search out related data, response era to craft replies, and high quality checking to make sure accuracy. Whereas GPT-4 can technically deal with all these duties, every requires totally different optimization. A mannequin skilled to excel at sentiment evaluation makes totally different architectural tradeoffs than one optimized for textual content era.
The breakthrough is not in constructing one mannequin to rule all of them. It is in coordinating a number of specialists.
This mirrors a sample we have seen earlier than in software program structure. Microservices changed monolithic functions not as a result of any single microservice was superior, however as a result of coordinated specialised companies proved extra maintainable, scalable, and efficient. AI is having its microservices second.
# The Three-Layer Stack
Understanding trendy AI functions requires pondering in layers. The structure that is emerged from manufacturing deployments seems remarkably constant.
// The Mannequin Layer
The Mannequin Layer sits on the basis. This consists of your LLMs, whether or not GPT-4, Claude, native fashions like Llama, or specialised fashions for imaginative and prescient, code, or evaluation. Every mannequin brings particular capabilities: reasoning, era, classification, or transformation. The important thing perception is that you just’re now not selecting one mannequin. You are composing a group.
// The Software Layer
The Software Layer allows motion. Language fashions can suppose however cannot do something on their very own. They want instruments to work together with the world. This layer consists of internet search, database queries, API calls, code execution environments, and file techniques. When Claude “searches the online” or ChatGPT “runs Python code,” they’re utilizing instruments from this layer. The Mannequin Context Protocol (MCP), just lately launched by Anthropic, is standardizing how fashions connect with instruments, making this layer more and more plug-and-play.
// The Orchestration Layer
The Orchestration Layer coordinates the whole lot. That is the place the intelligence of your system really lives. The orchestrator decides which mannequin to invoke for which activity, when to name instruments, chain operations collectively, and deal with failures. It is the conductor of your AI symphony.
Fashions are musicians, instruments are devices, and orchestration is the sheet music that tells everybody when to play.
# Orchestration Frameworks: Understanding the Patterns
Simply as React and Vue standardized frontend growth, orchestration frameworks are standardizing how we construct AI techniques. However earlier than we focus on particular instruments, we have to perceive the architectural patterns they symbolize. Instruments come and go. Patterns endure.
// The Chain Sample (Sequential Logic)
The Chain Sample (Sequential Logic) is orchestration’s most simple sample. Consider it as a knowledge pipeline the place every step’s output turns into the subsequent step’s enter. Person query, retrieve context, generate response, validate output. Every operation occurs in sequence, with the orchestrator managing the handoffs. LangChain pioneered this sample and constructed a whole framework round making chains composable and reusable.
The energy of chains lies of their simplicity: you’ll be able to purpose in regards to the circulation, debug step-by-step, and optimize particular person levels. The limitation is rigidity. Chains do not adapt primarily based on intermediate outcomes. If step two discovers the query is unanswerable, the chain nonetheless marches by way of steps three and 4. However for predictable workflows with clear levels, chains work properly.
// The RAG Sample (Retrieval-First Logic)
The RAG Sample (Retrieval-First Logic) emerged from a selected drawback: language fashions hallucinate once they lack data. The answer is easy: retrieve related data first, then generate responses grounded in that information.
However architecturally, RAG represents one thing deeper: Simply-in-Time Context Injection. Consider it because the separation of Compute (the LLM) from Reminiscence (the Vector Retailer). The mannequin itself stays static. It does not be taught new information. As a substitute, you swap what’s within the mannequin’s “RAM” by injecting related context into its immediate window. You are not retraining the mind. You are giving it entry to the precise data it wants, exactly when it wants it.
This architectural precept (Question, Search data base, Rank outcomes by relevance, Inject into context, Generate response) works as a result of it turns a generative drawback right into a retrieval plus synthesis drawback, and retrieval is extra dependable than era.
What makes this a long-lasting sample moderately than only a approach is that this separation of issues. The mannequin handles reasoning and synthesis. The vector retailer handles reminiscence and recall. The orchestrator manages the injection timing. LlamaIndex constructed its complete framework round optimizing this sample, dealing with the exhausting elements of doc chunking, embedding era, vector storage, and retrieval rating. You’ll be able to see how RAG works in follow even with easy no-code instruments.
// The Multi-Agent Sample (Delegation Logic)
The Multi-Agent Sample (Delegation Logic) represents orchestration’s most refined evolution. As a substitute of 1 sequential circulation or one retrieval step, you create specialised brokers that delegate to one another. A “planner” agent breaks down advanced duties. “Researcher” brokers collect data. “Analyst” brokers course of information. “Author” brokers produce output. “Critic” brokers evaluation high quality.
CrewAI exemplifies this sample, however the idea predates the software. The architectural perception is that advanced intelligence emerges from coordination between specialists, not from one generalist making an attempt to do the whole lot. Every agent has a slender accountability, clear success standards, and the power to request assist from different brokers. The orchestrator manages the delegation graph, making certain brokers do not loop infinitely and work progresses towards the purpose. If you wish to dive deeper into how brokers work collectively, take a look at key agentic AI ideas.
The selection between patterns is not about which is “finest.” It is about matching sample to drawback. Easy, predictable workflows? Use chains. Data-intensive functions? Use RAG. Advanced, multi-step reasoning requiring totally different specializations? Use multi-agent. Manufacturing techniques usually mix all three: a multi-agent system the place every agent makes use of RAG internally and communicates by way of chains.
The Mannequin Context Protocol deserves particular point out because the rising commonplace beneath these patterns. MCP is not a sample itself however a common protocol for a way fashions connect with instruments and information sources. Launched by Anthropic in late 2024, it is changing into the muse layer that frameworks construct upon, the HTTP of AI orchestration. As MCP adoption grows, we’re transferring towards standardized interfaces the place any sample can use any software, no matter which framework you have chosen.
# From Immediate to Pipeline: The Router Adjustments All the things
Understanding orchestration conceptually is one factor. Seeing it in manufacturing reveals why it issues and exposes the element that determines success or failure.
Contemplate a coding assistant that helps builders debug points. A single-model strategy would ship code and error messages to GPT-4 and hope for one of the best. An orchestrated system works in another way, and its success hinges on one essential element: the Router.
The Router is the decision-making engine on the coronary heart of each orchestrated system. It examines incoming requests and determines which pathway by way of your system they need to take. This is not simply plumbing. Routing accuracy determines whether or not your orchestrated system outperforms a single mannequin or wastes money and time on pointless complexity.
Let’s return to our debugging assistant. When a developer submits an issue, the Router should determine: Is that this a syntax error? A runtime error? A logic error? Every sort requires totally different dealing with.

How an Clever Router acts as a choice engine to direct inputs to specialised pathways | Picture by Writer
Syntax errors path to a specialised code analyzer, a light-weight mannequin fine-tuned for parsing violations. Runtime errors set off the debugger software to look at program state, then go findings to a reasoning mannequin that understands execution context. Logic errors require a distinct path totally: search Stack Overflow for comparable points, retrieve related context, then invoke a reasoning mannequin to synthesize options.
However how does the Router determine? Three approaches dominate manufacturing techniques.
Semantic routing makes use of embedding similarity. Convert the consumer’s query right into a vector, examine it to embeddings of instance questions for every route, and ship it down the trail with highest similarity. Quick and efficient for clearly distinct classes. The debugger makes use of this when error varieties are well-defined and examples are plentiful.
Key phrase routing examines specific alerts. If the error message incorporates “SyntaxError,” path to the parser. If it incorporates “NullPointerException,” path to the runtime handler. Easy, quick, and surprisingly strong when you’ve got dependable indicators. Many manufacturing techniques begin right here earlier than including complexity.
LLM-decision routing makes use of a small, quick mannequin because the Router itself. Ship the request to a specialised classification mannequin that is been skilled or prompted to make routing choices. Extra versatile than key phrases, extra dependable than pure semantic similarity, however provides latency and price. GitHub Copilot and comparable instruments use variations of this strategy.
Here is the perception that issues: The success of your orchestrated system relies upon 90% on Router accuracy, not on the sophistication of your downstream fashions. An ideal GPT-4 response despatched down the unsuitable path helps nobody. A good response from a specialised mannequin routed appropriately solves the issue.
This creates an sudden optimization goal. Groups obsess over which LLM to make use of for era however neglect Router engineering. They need to do the other. A easy Router making appropriate choices beats a posh Router that is ceaselessly unsuitable. Manufacturing groups measure routing accuracy religiously. It is the metric that predicts system success.
The Router additionally handles failures and fallbacks. What if semantic routing is not assured? What if the online search returns nothing? Manufacturing Routers implement determination bushes: strive semantic routing first, fall again to key phrase matching if confidence is low, escalate to LLM-decision routing for edge instances, and all the time preserve a default path for actually ambiguous inputs.
This explains why orchestrated techniques persistently outperform single fashions regardless of added complexity. It isn’t that orchestration magically makes fashions smarter. It is that correct routing ensures specialised fashions solely see issues they’re optimized to unravel. A syntax analyzer solely analyzes syntax. A reasoning mannequin solely causes. Every element operates in its zone of excellence as a result of the Router protected it from issues it will possibly’t deal with.
The structure sample is common: Router on the entrance, specialised processors behind it, orchestrator managing the circulation. Whether or not you are constructing a customer support bot, a analysis assistant, or a coding software, getting the Router proper determines whether or not your orchestrated system succeeds or turns into an costly, sluggish different to GPT-4.
# When to Orchestrate, When to Hold It Easy
Not each AI utility wants orchestration. A chatbot that solutions FAQs? Single mannequin. A system that classifies help tickets? Single mannequin. Producing product descriptions? Single mannequin.
Orchestration is sensible once you want:
A number of capabilities that no single mannequin handles properly. Customer support requiring sentiment evaluation, data retrieval, and response era advantages from orchestration. Easy Q&A does not.
Exterior information or actions. In case your AI wants to go looking databases, name APIs, or execute code, orchestration manages these software interactions higher than making an attempt to immediate a single mannequin to “fake” it will possibly entry information.
Reliability by way of redundancy. Manufacturing techniques usually chain a quick, low cost mannequin for preliminary processing with a succesful, costly mannequin for advanced instances. The orchestrator routes primarily based on issue.
Value optimization. Utilizing GPT-4 for the whole lot is pricey. Orchestration helps you to route easy duties to cheaper fashions and reserve costly fashions for exhausting issues.
The choice framework is simple: begin easy. Use a single mannequin till you hit clear limitations. Add orchestration when the complexity pays for itself in higher outcomes, decrease prices, or new capabilities.
# Ultimate Ideas
AI orchestration represents a maturation of the sector. We’re transferring from “which mannequin ought to I exploit?” to “how ought to I architect my AI system?” This mirrors each know-how’s evolution, from monolithic to distributed, from selecting one of the best software to composing the correct instruments.
The frameworks exist. The patterns are rising. The query now’s whether or not you may construct AI functions the previous approach (hoping one mannequin can do the whole lot) or the brand new approach: orchestrating specialised fashions and instruments into techniques which might be larger than the sum of their elements.
The way forward for AI is not find the right mannequin. It is in studying to conduct the orchestra.
Vinod Chugani is an AI and information science educator who bridges the hole between rising AI applied sciences and sensible utility for working professionals. His focus areas embrace agentic AI, machine studying functions, and automation workflows. By his work as a technical mentor and teacher, Vinod has supported information professionals by way of ability growth and profession transitions. He brings analytical experience from quantitative finance to his hands-on educating strategy. His content material emphasizes actionable methods and frameworks that professionals can apply instantly.