

{kind=link}
How can an AI system study to choose the fitting mannequin or software for every step of a process as an alternative of all the time counting on one giant mannequin for every part? NVIDIA researchers launch ToolOrchestra, a novel methodology for coaching a small language mannequin to behave because the orchestrator- the ‘mind’ of a heterogeneous tool-use agent
From Single Mannequin Brokers to an Orchestration Coverage
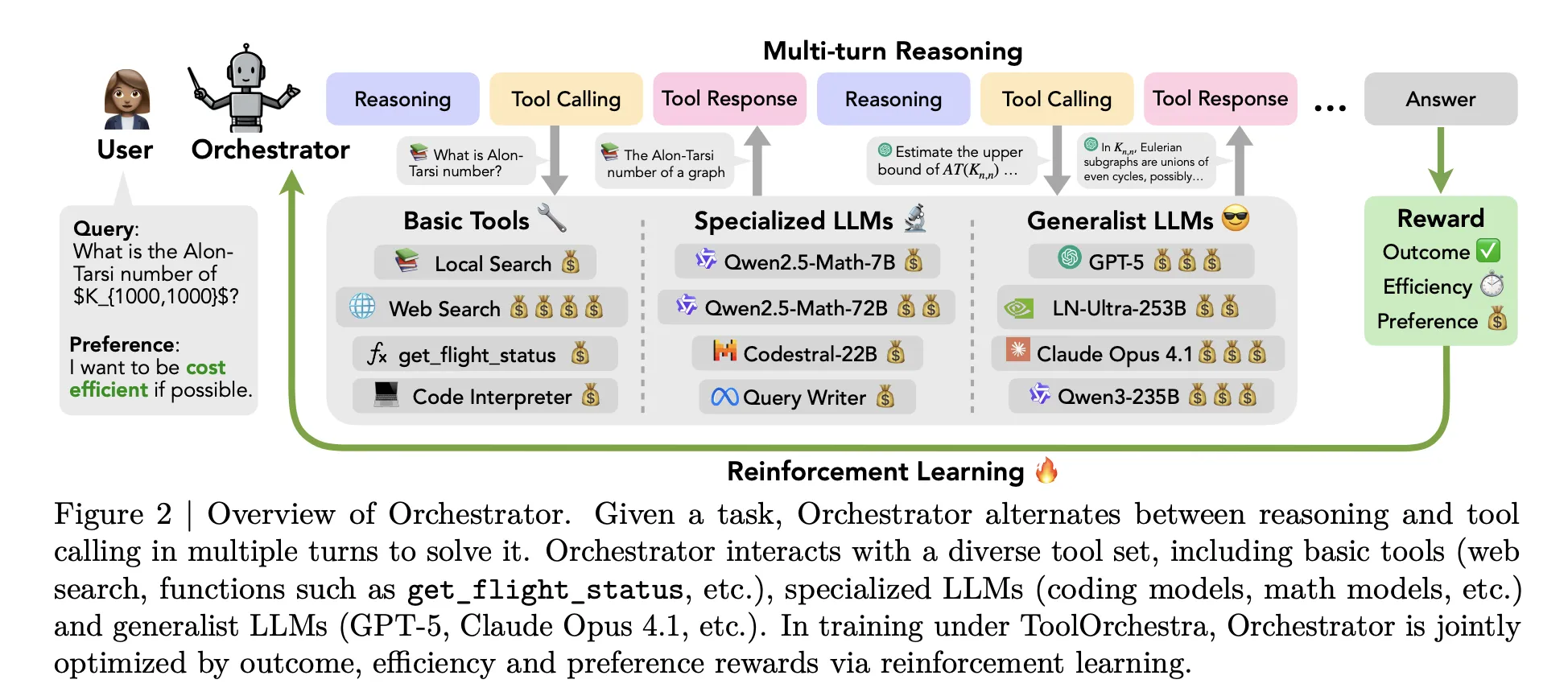
Most present brokers comply with a easy sample. A single giant mannequin corresponding to GPT-5 receives a immediate that describes obtainable instruments, then decides when to name net search or a code interpreter. All excessive degree reasoning nonetheless stays inside the identical mannequin. ToolOrchestra adjustments this setup. It trains a devoted controller mannequin known as as ‘Orchestrator-8B‘, that treats each basic instruments and different LLMs as callable elements.
A pilot research in the identical analysis reveals why naive prompting isn’t sufficient. When Qwen3-8B is prompted to route between GPT-5, GPT-5 mini, Qwen3-32B and Qwen2.5-Coder-32B, it delegates 73 % of circumstances to GPT-5. When GPT-5 acts as its personal orchestrator, it calls GPT-5 or GPT-5 mini in 98 % of circumstances. The analysis staff name these self enhancement and different enhancement biases. The routing coverage over makes use of sturdy fashions and ignores price directions.
ToolOrchestra as an alternative trains a small orchestrator explicitly for this routing drawback, utilizing reinforcement studying over full multi flip trajectories.
What’s Orchestrator 8B?
Orchestrator-8B is an 8B parameter decoder solely Transformer. It’s constructed by fantastic tuning Qwen3-8B as an orchestration mannequin and launched on Hugging Face.
At inference time, the system runs a multi flip loop that alternates reasoning and gear calls. The rollout has three predominant steps. First, Orchestrator 8B reads the consumer instruction and an optionally available pure language choice description, for instance a request to prioritize low latency or to keep away from net search. Second, it generates inner chain of thought type reasoning and plans an motion. Third, it chooses a software from the obtainable set and emits a structured software name in a unified JSON format. The surroundings executes that decision, appends the end result as an commentary and feeds it again into the following step. The method stops when a termination sign is produced or a most of fifty turns is reached.
Instruments cowl three predominant teams. Primary instruments embody Tavily net search, a Python sandbox code interpreter and an area Faiss index constructed with Qwen3-Embedding-8B. Specialised LLMs embody Qwen2.5-Math-72B, Qwen2.5-Math-7B and Qwen2.5-Coder-32B. Generalist LLM instruments embody GPT-5, GPT-5 mini, Llama 3.3-70B-Instruct and Qwen3-32B. All instruments share the identical schema with names, pure language descriptions and typed parameter specs.
Finish to Finish Reinforcement Studying with Multi Goal Rewards
ToolOrchestra formulates the entire workflow as a Markov Resolution Course of. The state accommodates the dialog historical past, previous software calls and observations, and consumer preferences. Actions are the following textual content step, together with each reasoning tokens and a software name schema. After as much as 50 steps, the surroundings computes a scalar reward for the total trajectory.
The reward has three elements. Consequence reward is binary and is determined by whether or not the trajectory solves the duty. For open-ended solutions, GPT-5 is used as a decide to match the mannequin output with the reference. Effectivity rewards penalize each financial price and wall clock latency. Token utilization for proprietary and open supply instruments is mapped to financial price utilizing public API and Collectively AI pricing. Choice reward measures how effectively software utilization matches a consumer choice vector that may enhance or lower the burden on price, latency or particular instruments. These elements are mixed right into a single scalar utilizing the choice vector.
The coverage is optimized with Group Relative Coverage Optimization GRPO, a variant of coverage gradient reinforcement studying that normalizes rewards inside teams of trajectories for a similar process. The coaching course of contains filters that drop trajectories with invalid software name format or weak reward variance to stabilize optimization.
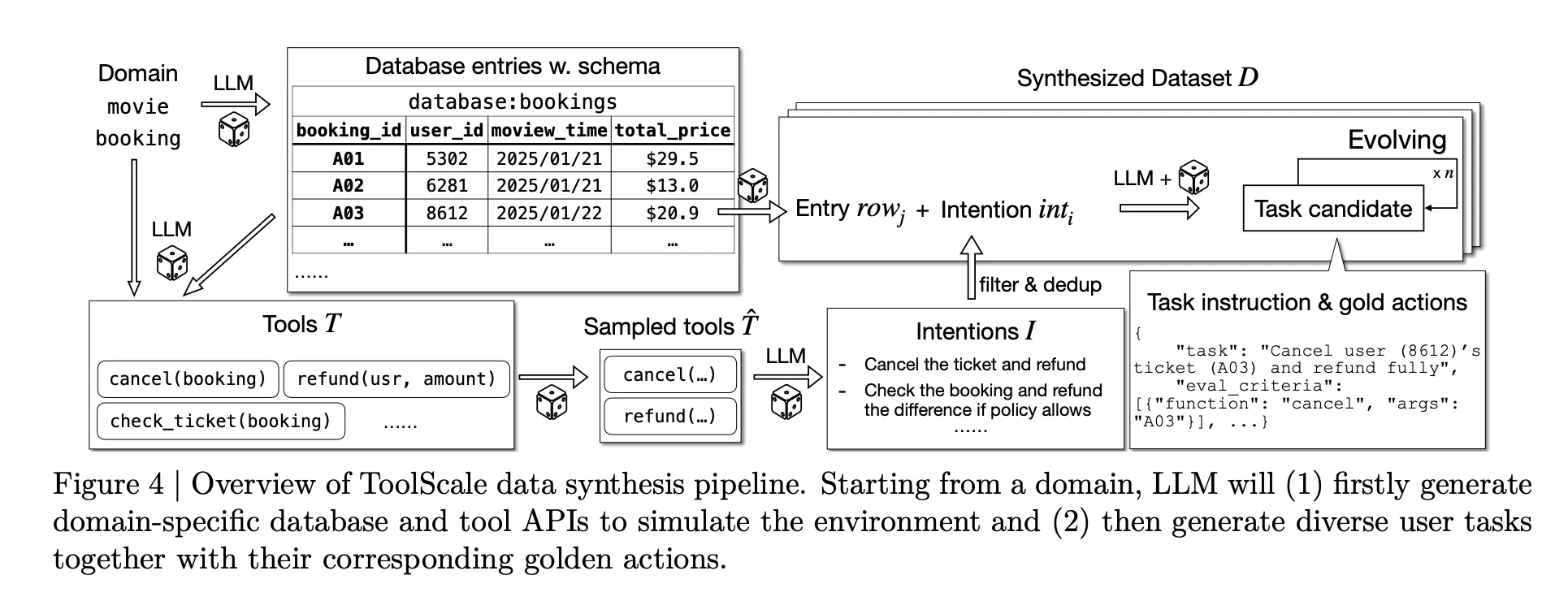
To make this coaching attainable at scale, the analysis staff plans to introduce ToolScale, an artificial dataset of multi step software calling duties. For every area, an LLM generates a database schema, database entries, area particular APIs after which numerous consumer duties with floor reality sequences of perform calls and required intermediate data.
Benchmark outcomes and price profile
NVIDIA analysis staff evaluates Orchestrator-8B on three difficult benchmarks, Humanity’s Final Examination, FRAMES and τ² Bench. These benchmarks goal lengthy horizon reasoning, factuality below retrieval and performance calling in a twin management surroundings.
On Humanity’s Final Examination textual content solely questions, Orchestrator-8B reaches 37.1 % accuracy. GPT-5 with primary instruments reaches 35.1 % in the identical setting. On FRAMES, Orchestrator-8B achieves 76.3 % versus 74.0 % for GPT-5 with instruments. On τ² Bench, Orchestrator-8B scores 80.2 % versus 77.7 % for GPT-5 with primary instruments.

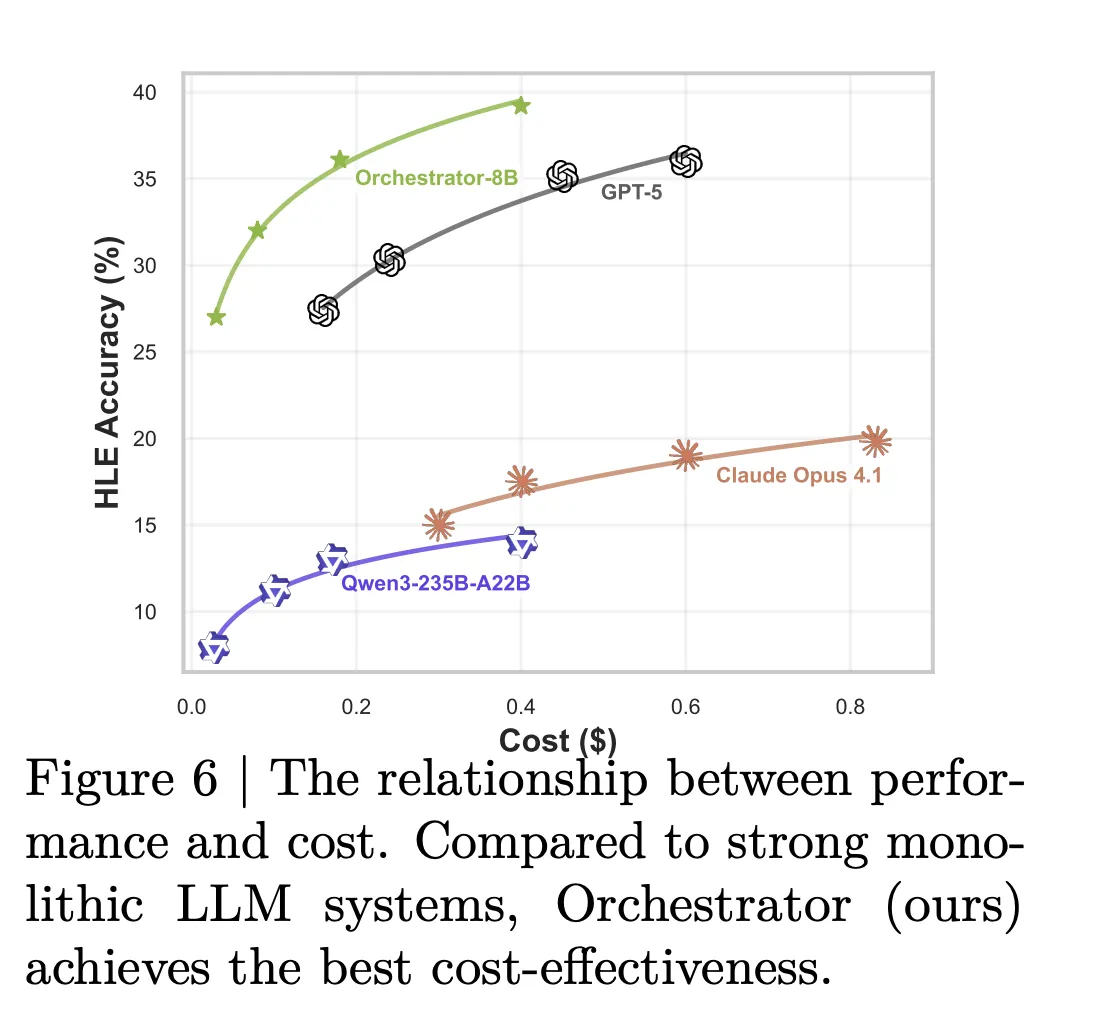
The effectivity hole is bigger. Within the configuration that makes use of primary instruments plus specialised and generalist LLM instruments, Orchestrator-8B has common price 9.2 cents and latency 8.2 minutes per question, averaged over Humanity’s Final Examination and FRAMES. In the identical configuration, GPT-5 prices 30.2 cents and takes 19.8 minutes on common. The mannequin card summarizes this as about 30 % of the financial price and a pair of.5 occasions quicker for Orchestrator-8B in comparison with GPT-5.
Software use evaluation helps this image. Claude Opus 4.1 used as an orchestrator calls GPT-5 more often than not. GPT-5 used as an orchestrator prefers GPT-5 mini. Orchestrator-8B spreads calls extra evenly throughout sturdy fashions, cheaper fashions, search, native retrieval and the code interpreter, and reaches greater accuracy at decrease price for a similar flip finances.
Generalization experiments substitute the coaching time instruments with unseen fashions corresponding to OpenMath Llama-2-70B, DeepSeek-Math-7B-Instruct, Codestral-22B-v0.1, Claude Sonnet-4.1 and Gemma-3-27B. Orchestrator-8B nonetheless achieves the most effective commerce off between accuracy, price and latency amongst all baselines on this setting. A separate choice conscious take a look at set reveals that Orchestrator-8B additionally tracks consumer software utilization preferences extra intently than GPT-5, Claude Opus-4.1 and Qwen3-235B-A22B below the identical reward metric.
Key Takeaways
- ToolOrchestra trains an 8B parameter orchestration mannequin, Orchestrator-8B, that selects and sequences instruments and LLMs to unravel multi step agentic duties utilizing reinforcement studying with end result, effectivity and choice conscious rewards.
- Orchestrator-8B is launched as an open weight mannequin on Hugging Face. It’s designed to coordinate numerous instruments corresponding to net search, code execution, retrieval and specialist LLMs via a unified schema.
- On Humanity’s Final Examination, Orchestrator-8B reaches 37.1 % accuracy, surpassing GPT-5 at 35.1 %, whereas being about 2.5 occasions extra environment friendly, and on τ² Bench and FRAMES it outperforms GPT-5 whereas utilizing roughly 30 % of the associated fee.
- The framework reveals that naive prompting of a frontier LLM as its personal router results in self enhancement bias the place it overuses itself or a small set of sturdy fashions, whereas a skilled orchestrator learns a extra balanced, price conscious routing coverage over a number of instruments.
Editorial Notes
NVIDIA’s ToolOrchestra is a sensible step towards compound AI methods the place an 8B orchestration mannequin, Orchestrator-8B, learns an express routing coverage over instruments and LLMs as an alternative of counting on a single frontier mannequin. It reveals clear beneficial properties on Humanity’s Final Examination, FRAMES and τ² Bench with about 30 % of the associated fee and round 2.5 occasions higher effectivity than GPT-5 primarily based baselines, which makes it instantly related for groups that care about accuracy, latency and finances. This launch makes orchestration coverage a first-class optimization goal in AI methods.
Take a look at the Paper, Repo, Challenge Web page and Mannequin Weights. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.