

{kind=link}
What for those who might tune multimodal retrieval at serve time—buying and selling accuracy, latency, and index measurement—just by selecting what number of learnable Meta Tokens (e.g., 1→16 for queries, 1→64 for candidates) to make use of? Meta Superintelligence Labs introduces MetaEmbed, a late-interaction recipe for multimodal retrieval that exposes a single management floor at serving time: what number of compact “Meta Tokens” to make use of on the question and candidate sides. Quite than collapsing every merchandise into one vector (CLIP-style) or exploding into lots of of patch/token vectors (ColBERT-style), MetaEmbed appends a set, learnable set of Meta Tokens in coaching and reuses their last hidden states as multi-vector embeddings at inference. The method permits test-time scaling—operators can commerce accuracy for latency and index measurement by choosing a retrieval price range with out retraining.
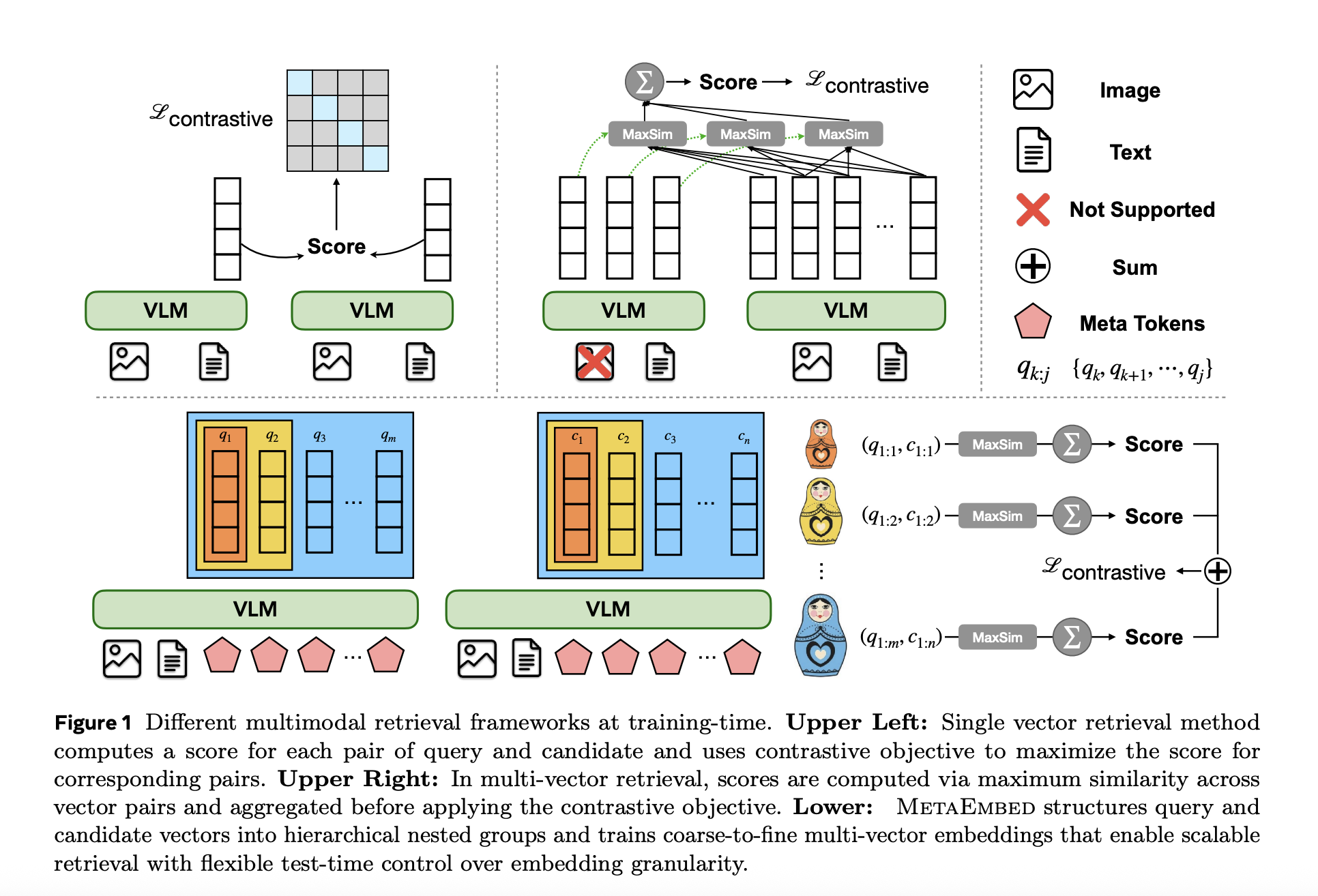
How MetaEmbed works?
The system trains with Matryoshka Multi-Vector Retrieval (MMR): Meta Tokens are organized into prefix-nested teams so every prefix is independently discriminative. At inference, the retrieval price range is a tuple ((r_q, r_c)) specifying what number of query-side and candidate-side Meta Tokens to make use of (e.g., ((1,1),(2,4),(4,8),(8,16),(16,64))). Scoring makes use of a ColBERT-like MaxSim late-interaction over L2-normalized Meta Token embeddings, preserving fine-grained cross-modal element whereas conserving the vector set small.
Benchmarks
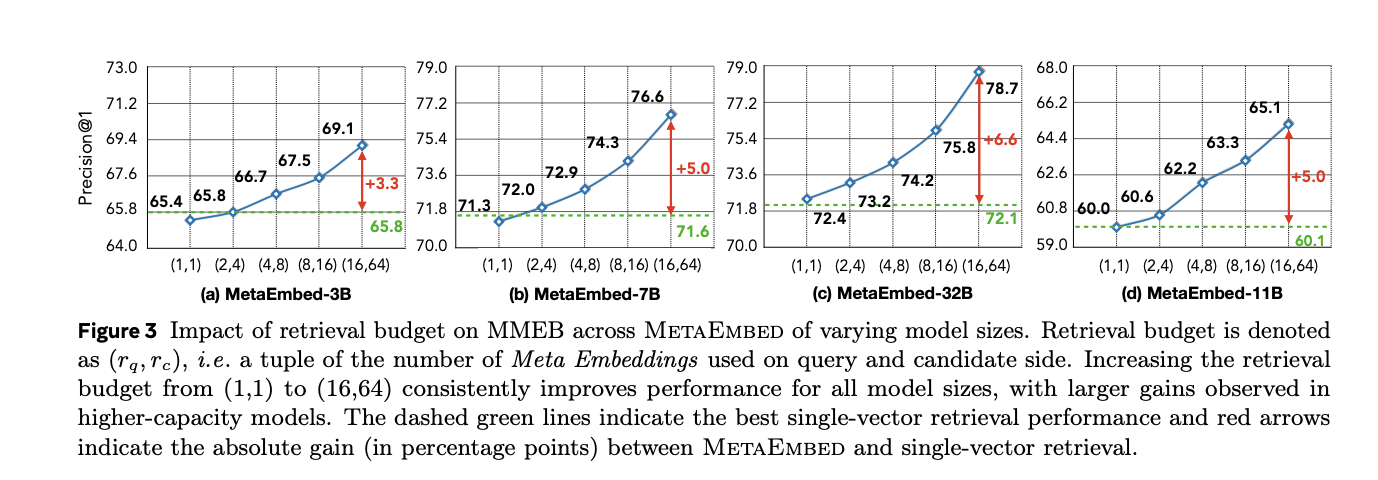
MetaEmbed is evaluated on MMEB (Large Multimodal Embedding Benchmark) and ViDoRe v2 (Visible Doc Retrieval), each designed to emphasize retrieval beneath numerous modalities and extra sensible doc queries. On MMEB, MetaEmbed with Qwen2.5-VL backbones stories general scores on the largest price range ((16,64)): 3B = 69.1, 7B = 76.6, 32B = 78.7. Good points are monotonic because the price range will increase and widen with mannequin scale. On ViDoRe v2, the tactic improves common nDCG@5 versus single-vector and a naive fixed-length multi-vector baseline beneath an identical coaching, with the hole rising at increased budgets.
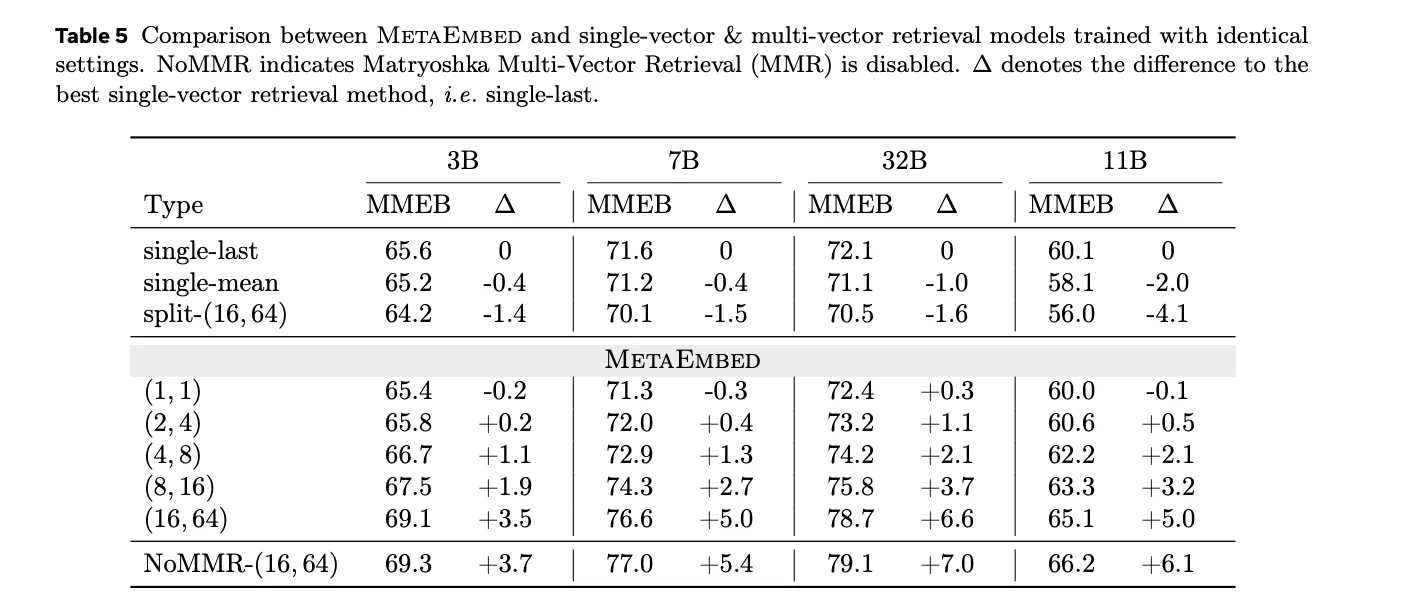
Ablations affirm that MMR delivers the test-time scaling property with out sacrificing full-budget high quality. When MMR is disabled (NoMMR), efficiency at low budgets collapses; with MMR enabled, MetaEmbed tracks or exceeds single-vector baselines throughout budgets and mannequin sizes.
Effectivity and reminiscence
With 100k candidates per question and a scoring batch measurement of 1,000, the analysis stories scoring value and index reminiscence on an A100. Because the price range grows from ((1,1)) to ((16,64)), scoring FLOPs enhance from 0.71 GFLOPs → 733.89 GFLOPs, scoring latency from 1.67 ms → 6.25 ms, and bfloat16 index reminiscence from 0.68 GiB → 42.72 GiB. Crucially, question encoding dominates end-to-end latency: encoding a picture question with 1,024 tokens is 42.72 TFLOPs and 788 ms, a number of orders bigger than scoring for small candidate units. Operators ought to subsequently give attention to encoder throughput and handle index progress by selecting balanced budgets or offloading indexes to CPU when mandatory.
The way it compares?
- Single-vector (CLIP-style): minimal index and quick dot-product scoring however restricted instruction sensitivity and compositional element; MetaEmbed improves precision through the use of a small, contextual multi-vector set whereas preserving impartial encoding.
- Naive multi-vector (ColBERT-style) on multimodal↔multimodal: wealthy token-level element however prohibitive index measurement and compute when each side embody photographs; MetaEmbed’s few Meta Tokens scale back vectors by orders of magnitude and permit budgeted MaxSim.
Takeaways
- One mannequin, many budgets. Prepare as soon as; select ((r_q, r_c)) at serve time for recall vs. value. Low budgets are appropriate for preliminary retrieval; excessive budgets might be reserved for re-ranking phases.
- Encoder is the bottleneck. Optimize picture tokenization and VLM throughput; scoring stays light-weight for typical candidate set sizes.
- Reminiscence scales linearly with price range. Plan index placement and sharding (GPU vs. CPU) across the chosen ((r_q, r_c)).
Editorial Notes
MetaEmbed contributes a serving-time management floor for multimodal retrieval: nested, coarse-to-fine Meta Tokens educated with MMR yield compact multi-vector embeddings whose granularity is adjustable after coaching. The outcomes present constant accuracy good points over single-vector and naive multi-vector baselines on MMEB and ViDoRe v2, whereas clarifying the sensible value profile—encoder-bound latency, budget-dependent index measurement, and millisecond-scale scoring on commodity accelerators. For groups constructing retrieval stacks that should unify quick recall and exact re-ranking throughout picture–textual content and visual-document eventualities, the recipe is straight actionable with out architectural rewrites.
Try the PAPER right here. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.