

{kind=link}
How do you design a single mannequin that may pay attention, see, learn and reply in actual time throughout textual content, picture, video and audio with out dropping the effectivity? Meituan’s LongCat staff has launched LongCat Flash Omni, an open supply omni modal mannequin with 560 billion parameters and about 27 billion energetic per token, constructed on the shortcut related Combination of Consultants design that LongCat Flash launched. The mannequin extends the textual content spine to imaginative and prescient, video and audio, and it retains a 128K context so it could run lengthy conversations and doc degree understanding in a single stack.
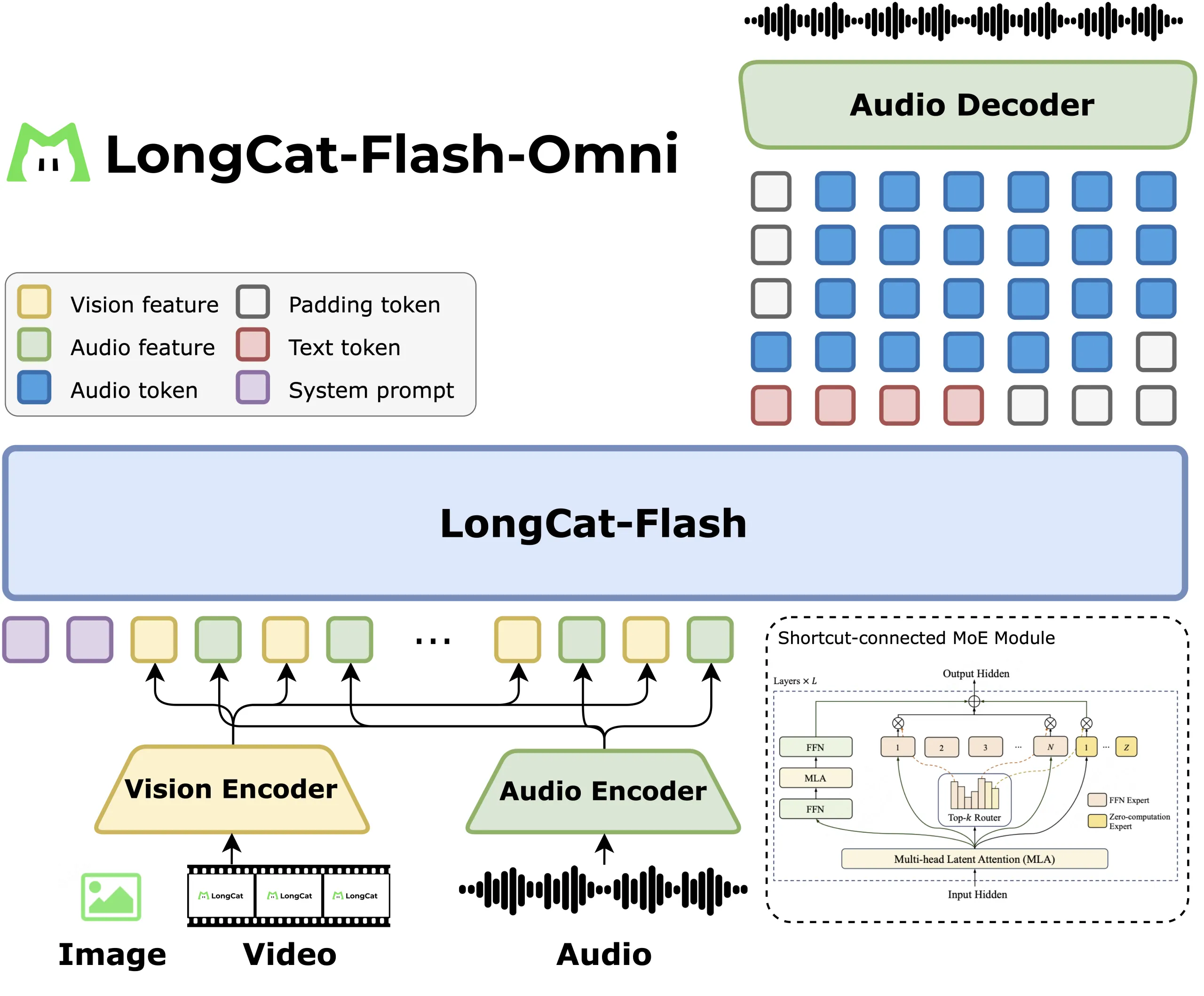
Structure and Modal Attachments
LongCat Flash Omni retains the language mannequin unchanged, then provides notion modules. A LongCat ViT encoder processes each pictures and video frames so there isn’t any separate video tower. An audio encoder along with the LongCat Audio Codec turns speech into discrete tokens, then the decoder can output speech from the identical LLM stream, which permits actual time audio visible interplay.
Streaming and Characteristic Interleaving
The analysis staff describes chunk sensible audio visible function interleaving, the place audio options, video options and timestamps are packed into 1 second segments. Video is sampled at 2 frames per second by default, then the speed is adjusted in response to video size, the report doesn’t tie the sampling rule to person or mannequin talking phases, so the right description is length conditioned sampling. This retains latency low and nonetheless offers spatial context for GUI, OCR and video QA duties.
Curriculum from Textual content to Omni
Coaching follows a staged curriculum. The analysis staff first trains the LongCat Flash textual content spine, which prompts 18.6B to 31.3B parameters per token, common 27B, then applies textual content speech continued pretraining, then multimodal continued pretraining with picture and video, then context extension to 128K, then audio encoder alignment.
Methods Design, Modality Decoupled Parallelism
As a result of the encoders and the LLM have completely different compute patterns, Meituan makes use of modality decoupled parallelism. Imaginative and prescient and audio encoders run with hybrid sharding and activation recomputation, the LLM runs with pipeline, context and professional parallelism, and a ModalityBridge aligns embeddings and gradients. The analysis staff stories that multimodal supervised tremendous tuning retains greater than 90 % of the throughput of textual content solely coaching, which is the principle methods end result on this launch.
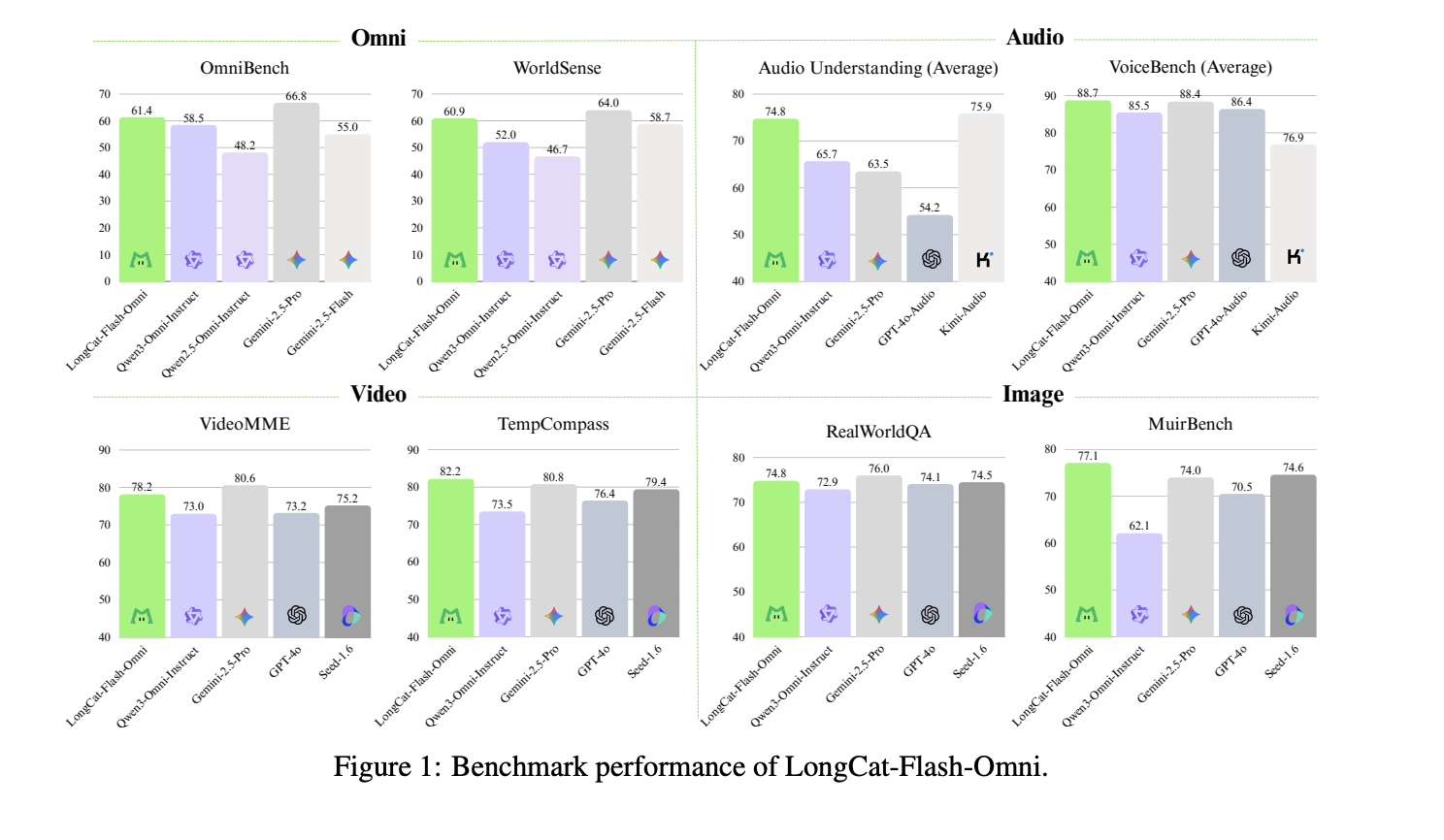
Benchmarks and Positioning
LongCat Flash Omni reaches 61.4 on OmniBench, that is greater than Qwen 3 Omni Instruct at 58.5 and Qwen 2.5 Omni at 55.0, however decrease than Gemini 2.5 Professional at 66.8. On VideoMME it scores 78.2, which is near GPT 4o and Gemini 2.5 Flash, and on VoiceBench it reaches 88.7, barely greater than GPT 4o Audio in the identical desk.
Key Takeaways
- LongCat Flash Omni is an open supply omni modal mannequin constructed on Meituan’s 560B MoE spine, it prompts about 27B parameters per token by way of shortcut related MoE with zero computation consultants, so it retains massive capability however inference pleasant compute.
- The mannequin attaches unified imaginative and prescient video encoding and a streaming audio path to the prevailing LongCat Flash LLM, utilizing 2 fps default video sampling with length conditioned adjustment, and packs audio visible options into 1 second chunks for synchronized decoding, which is what permits actual time any to any interplay.
- LongCat Flash Omni scores 61.4 on OmniBench, above Qwen 3 Omni Instruct at 58.5, however under Gemini 2.5 Professional at 66.8.
- Meituan makes use of modality decoupled parallelism, imaginative and prescient and audio encoders run with hybrid sharding, the LLM runs with pipeline, context and professional parallelism, and report greater than 90 % of textual content solely throughput for multimodal SFT, which is the principle methods contribution of the discharge.
This launch reveals that Meituan is attempting to make omni modal interplay sensible, not experimental. It retains the 560B Shortcut related Combination of Consultants with 27B activated, so the language spine stays suitable with earlier LongCat releases. It provides streaming audio visible notion with 2 fps default video sampling and length conditioned adjustment, so latency stays low with out dropping spatial grounding. It stories over 90 % textual content solely throughput in multimodal supervised tremendous tuning by way of modality decoupled parallelism.
Try the Paper, Mannequin Weights and GitHub Repo. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as effectively.

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking complicated datasets into actionable insights.