

{kind=link}
TLDR: VISTA is a multi agent framework that improves textual content to video technology throughout inference, it plans structured prompts as scenes, runs a pairwise match to pick one of the best candidate, makes use of specialised judges throughout visible, audio, and context, then rewrites the immediate with a Deep Considering Prompting Agent, the strategy exhibits constant features over sturdy immediate optimization baselines in single scene and multi scene settings, and human raters choose its outputs.
What VISTA is?
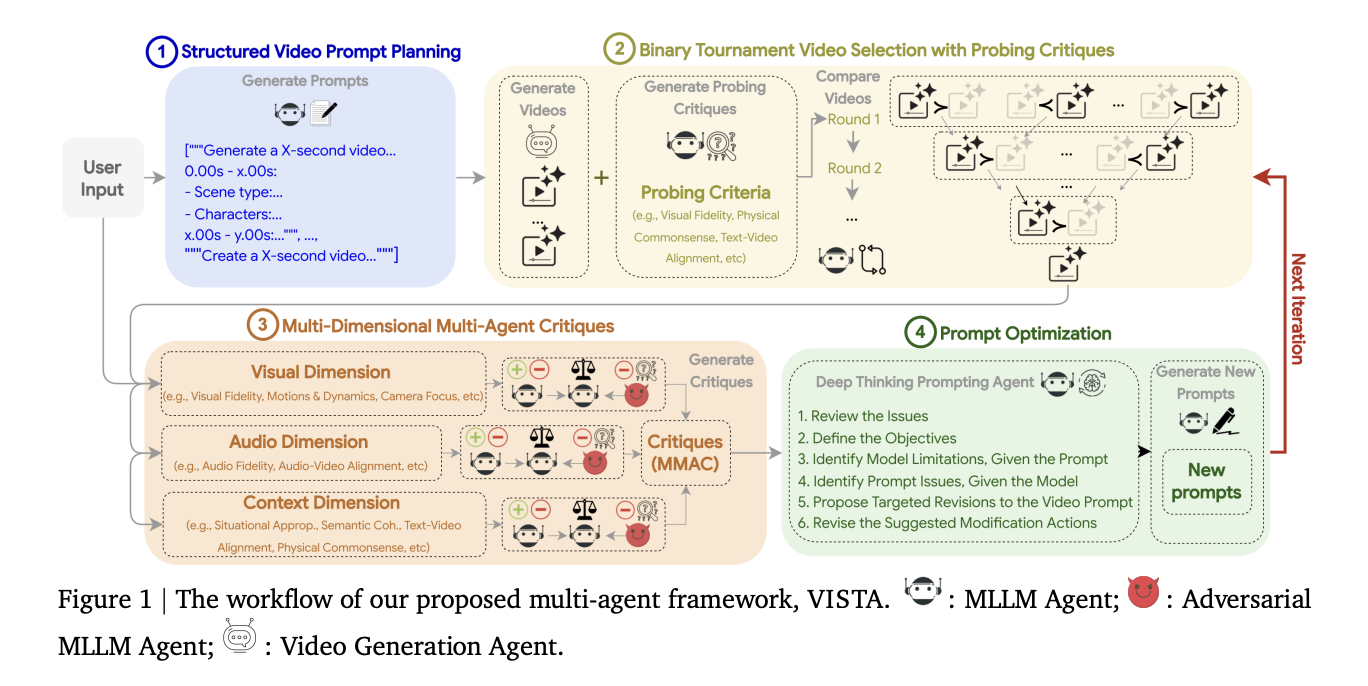
VISTA stands for Video Iterative Self improvemenT Agent. It’s a black field, multi agent loop that refines prompts and regenerates movies at check time. The system targets 3 features collectively, visible, audio, and context. It follows 4 steps, structured video immediate planning, pairwise match choice, multi dimensional multi agent critiques, and a Deep Considering Prompting Agent for immediate rewriting.
The analysis group evaluates VISTA on a single scene benchmark and on an inside multi scene set. It studies constant enhancements and as much as 60 p.c pairwise win price in opposition to cutting-edge baselines in some settings, and a 66.4 p.c human choice over the strongest baseline.

Understanding the important thing drawback
Textual content to video fashions like Veo 3 can produce prime quality video and audio, but outputs stay delicate to precise immediate phrasing, adherence to physics can fail, and alignment to consumer objectives can drift, which forces guide trial and error. VISTA frames this as a check time optimization drawback. It seeks unified enchancment throughout visible indicators, audio indicators, and contextual alignment.
How VISTA works, step-by-step?
Step 1: structured video immediate planning
The consumer immediate is decomposed into timed scenes. Every scene carries 9 properties, length, scene kind, characters, actions, dialogues, visible surroundings, digicam, sounds, moods. A multimodal LLM fills lacking properties and enforces constraints on realism, relevancy, and creativity by default. The system additionally retains the unique consumer immediate within the candidate set to permit fashions that don’t profit from decomposition.
Step 2: pairwise match video choice
The system samples a number of video, immediate pairs. An MLLM acts as a choose with binary tournaments and bidirectional swapping to cut back token order bias. The default standards embody visible constancy, bodily commonsense, textual content video alignment, audio video alignment, and engagement. The strategy first elicits probing critiques to assist evaluation, then performs pairwise comparability, and applies customizable penalties for frequent textual content to video failures.
Step 3: multi dimensional multi agent critiques
The champion video and immediate obtain critiques alongside 3 dimensions, visible, audio, and context. Every dimension makes use of a triad, a traditional choose, an adversarial choose, and a meta choose that consolidates either side. Metrics embody visible constancy, motions and dynamics, temporal consistency, digicam focus, and visible security for visible, audio constancy, audio video alignment, and audio security for audio, situational appropriateness, semantic coherence, textual content video alignment, bodily commonsense, engagement, and video format for context. Scores are on a 1 to 10 scale, which helps focused error discovery.
Step 4: Deep Considering Prompting Agent
The reasoning module reads the meta critiques and runs a 6 step introspection, it identifies low scoring metrics, clarifies anticipated outcomes, checks immediate sufficiency, separates mannequin limits from immediate points, detects conflicts or vagueness, proposes modification actions, then samples refined prompts for the following technology cycle.

Understanding the outcomes
Automated analysis: The analysis research studies win, tie, loss charges on ten standards utilizing an MLLM as a choose, with bidirectional comparisons. VISTA achieves a win price over direct prompting that rises throughout iterations, reaching 45.9 p.c in single scene and 46.3 p.c in multi scene at iteration 5. It additionally wins immediately in opposition to every baseline below the identical compute price range.
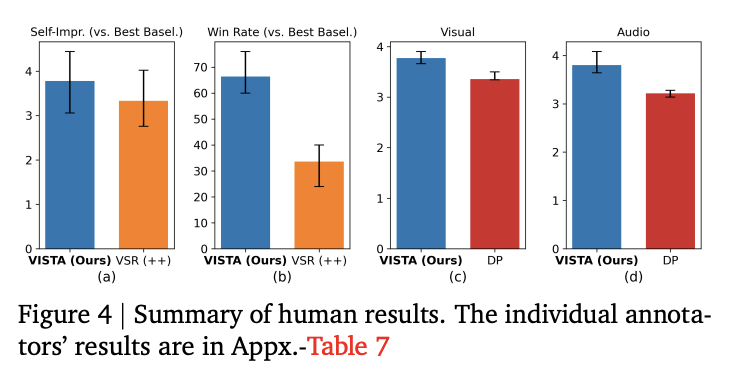
Human research: Annotators with immediate optimization expertise choose VISTA in 66.4 p.c of face to face trials in opposition to one of the best baseline at iteration 5. Consultants price optimization trajectories larger for VISTA, and so they rating visible high quality and audio high quality larger than direct prompting.
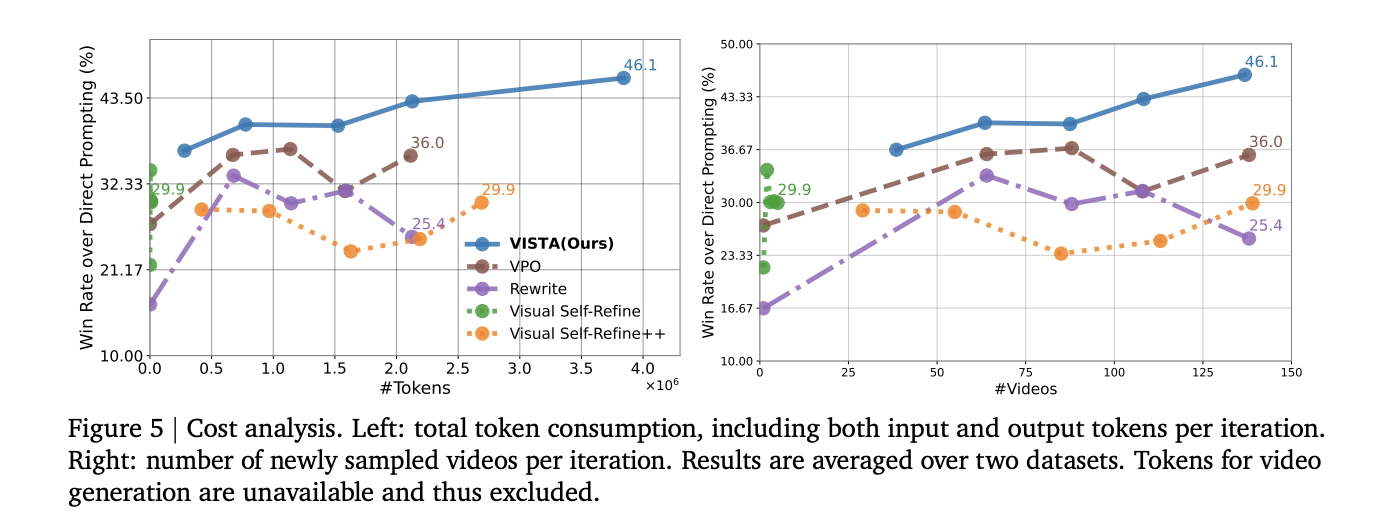
Price and scaling: Common tokens per iteration are about 0.7 million throughout two datasets, technology tokens should not included. Most token use comes from choice and critiques, which course of movies as lengthy context inputs. Win price tends to extend because the variety of sampled movies and tokens per iteration will increase.
Ablations: Eradicating immediate planning weakens initialization. Eradicating match choice destabilizes later iterations. Utilizing just one choose kind reduces efficiency. Eradicating the Deep Considering Prompting Agent lowers remaining win charges.
Evaluators: The analysis group repeated analysis with various evaluator fashions and observe comparable iterative enhancements, which helps robustness of the development.
Key Takeaways
- VISTA is a check time, multi agent loop that collectively optimizes visible, audio, and context for textual content to video technology.
- It plans prompts as timed scenes with 9 attributes, length, scene kind, characters, actions, dialogues, visible surroundings, digicam, sounds, moods.
- Candidate movies are chosen through pairwise tournaments utilizing an MLLM choose with bidirectional swap, scored on visible constancy, bodily commonsense, textual content video alignment, audio video alignment, and engagement.
- A triad of judges per dimension, regular, adversarial, meta, produces 1 to 10 scores that information the Deep Considering Prompting Agent to rewrite the immediate and iterate.
- Outcomes present 45.9 p.c wins on single scene and 46.3 p.c on multi scene at iteration 5 over direct prompting, human raters choose VISTA in 66.4 p.c of trials, common token value per iteration is about 0.7 million.
VISTA is a sensible step towards dependable textual content to video technology, it treats inference as an optimization loop and retains the generator as a black field. The structured video immediate planning is beneficial for early engineers, the 9 scene attributes give a concrete guidelines. The pairwise match choice with a multimodal LLM choose and bidirectional swap is a smart solution to cut back ordering bias, the standards goal actual failure modes, visible constancy, bodily commonsense, textual content video alignment, audio video alignment, engagement. The multi dimensional critiques separate visible, audio, and context, the conventional, adversarial, and meta judges expose weaknesses that single judges miss. The Deep Considering Prompting Agent turns these diagnostics into focused immediate edits. Using Gemini 2.5 Flash and Veo 3 clarifies the reference setup, the Veo 2 research is a useful decrease sure. The reported 45.9 and 46.3 p.c win charges and 66.4 p.c human choice point out repeatable features. The 0.7 million token value is non trivial, but clear and scalable.
Take a look at the Paper and Mission Web page. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as nicely.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.