

{kind=link}
The Downside with “Considering Longer”
Massive language fashions have made spectacular strides in mathematical reasoning by extending their Chain-of-Thought (CoT) processes—basically “pondering longer” via extra detailed reasoning steps. Nevertheless, this strategy has elementary limitations. When fashions encounter delicate errors of their reasoning chains, they usually compound these errors moderately than detecting and correcting them. Inside self-reflection continuously fails, particularly when the preliminary reasoning strategy is essentially flawed.
Microsoft’s new analysis report introduces rStar2-Agent, that takes a unique strategy: as an alternative of simply pondering longer, it teaches fashions to assume smarter by actively utilizing coding instruments to confirm, discover, and refine their reasoning course of.
The Agentic Strategy
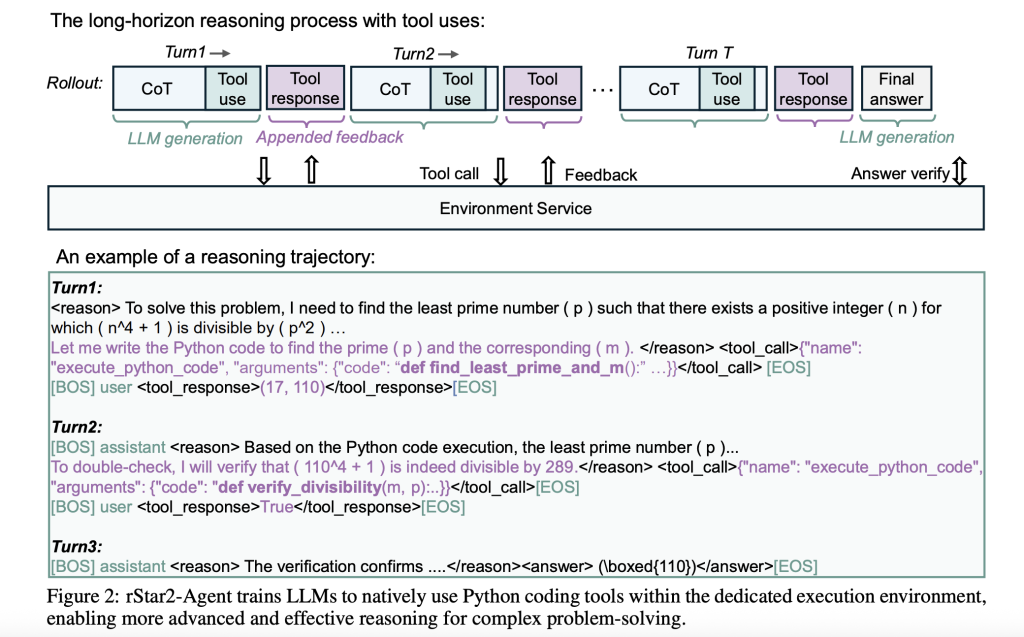
rStar2-Agent represents a shift towards agentic reinforcement studying, the place a 14B parameter mannequin interacts with a Python execution setting all through its reasoning course of. Reasonably than relying solely on inside reflection, the mannequin can write code, execute it, analyze the outcomes, and modify its strategy based mostly on concrete suggestions.
This creates a dynamic problem-solving course of. When the mannequin encounters a posh mathematical downside, it would generate preliminary reasoning, write Python code to check hypotheses, analyze execution outcomes, and iterate towards an answer. The strategy mirrors how human mathematicians usually work—utilizing computational instruments to confirm intuitions and discover totally different answer paths.
Infrastructure Challenges and Options
Scaling agentic RL presents vital technical hurdles. Throughout coaching, a single batch can generate tens of 1000’s of concurrent code execution requests, creating bottlenecks that may stall GPU utilization. The researchers addressed this with two key infrastructure improvements.
First, they constructed a distributed code execution service able to dealing with 45,000 concurrent software calls with sub-second latency. The system isolates code execution from the principle coaching course of whereas sustaining excessive throughput via cautious load balancing throughout CPU staff.
Second, they developed a dynamic rollout scheduler that allocates computational work based mostly on real-time GPU cache availability moderately than static task. This prevents GPU idle time attributable to uneven workload distribution—a standard downside when some reasoning traces require considerably extra computation than others.
These infrastructure enhancements enabled your complete coaching course of to finish in only one week utilizing 64 AMD MI300X GPUs, demonstrating that frontier-level reasoning capabilities don’t require huge computational sources when effectively orchestrated.
GRPO-RoC: Studying from Excessive-High quality Examples
The core algorithmic innovation is Group Relative Coverage Optimization with Resampling on Right (GRPO-RoC). Conventional reinforcement studying on this context faces a top quality downside: fashions obtain optimistic rewards for proper remaining solutions even when their reasoning course of contains a number of code errors or inefficient software utilization.
GRPO-RoC addresses this by implementing an uneven sampling technique. Throughout coaching, the algorithm:
- Oversamples preliminary rollouts to create a bigger pool of reasoning traces
- Preserves range in failed makes an attempt to keep up studying from varied error modes
- Filters optimistic examples to emphasise traces with minimal software errors and cleaner formatting
This strategy ensures the mannequin learns from high-quality profitable reasoning whereas nonetheless publicity to numerous failure patterns. The result’s extra environment friendly software utilization and shorter, extra centered reasoning traces.
Coaching Technique: From Easy to Advanced
The coaching course of unfolds in three rigorously designed levels, beginning with non-reasoning supervised fine-tuning that focuses purely on instruction following and power formatting—intentionally avoiding complicated reasoning examples that may create early biases.
Stage 1 constrains responses to eight,000 tokens, forcing the mannequin to develop concise reasoning methods. Regardless of this limitation, efficiency jumps dramatically—from near-zero to over 70% on difficult benchmarks.
Stage 2 extends the token restrict to 12,000, permitting for extra complicated reasoning whereas sustaining the effectivity good points from the primary stage.
Stage 3 shifts focus to probably the most tough issues by filtering out these the mannequin has already mastered, guaranteeing continued studying from difficult instances.
This development from concise to prolonged reasoning, mixed with growing downside problem, maximizes studying effectivity whereas minimizing computational overhead.
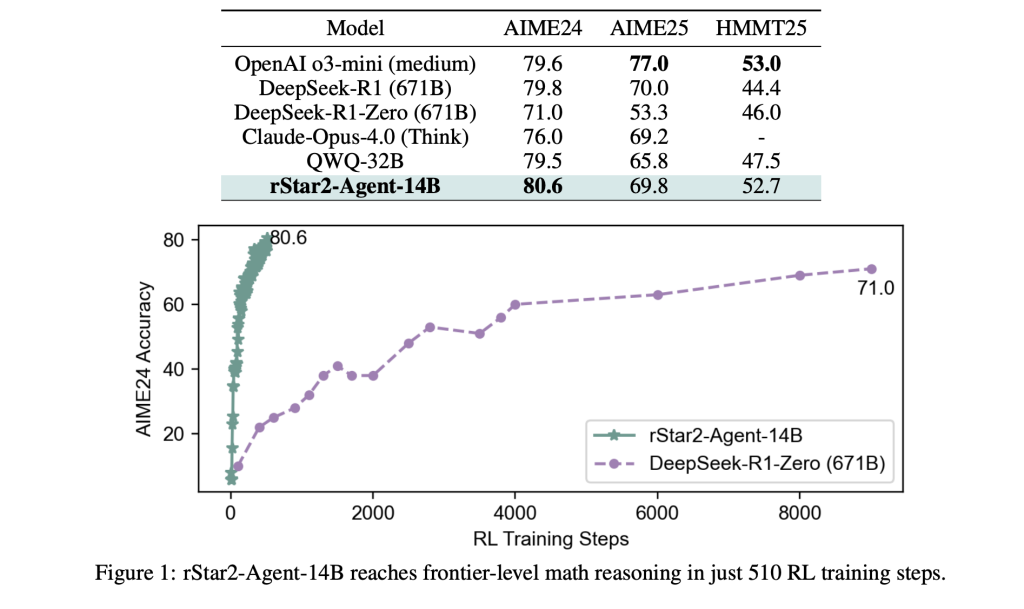
Breakthrough Outcomes
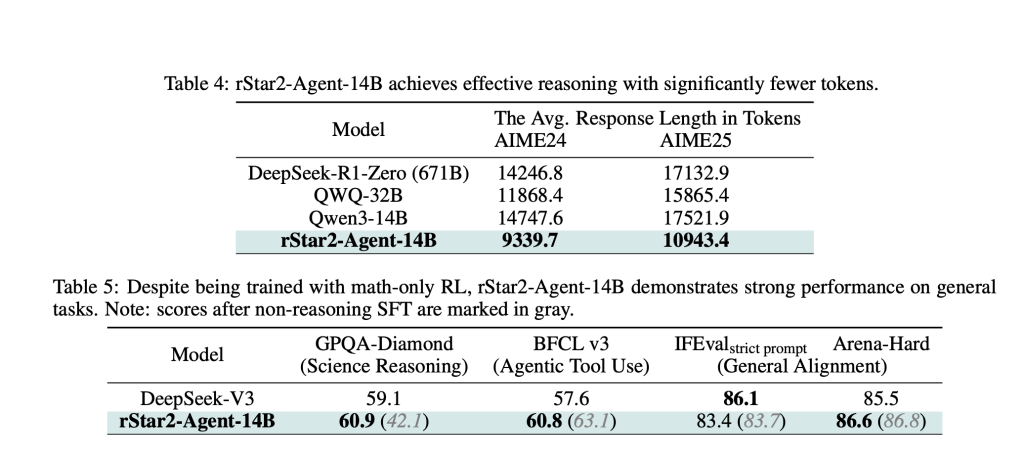
The outcomes are hanging. rStar2-Agent-14B achieves 80.6% accuracy on AIME24 and 69.8% on AIME25, surpassing a lot bigger fashions together with the 671B parameter DeepSeek-R1. Maybe extra importantly, it accomplishes this with considerably shorter reasoning traces—averaging round 10,000 tokens in comparison with over 17,000 for comparable fashions.
The effectivity good points prolong past arithmetic. Regardless of coaching solely on math issues, the mannequin demonstrates sturdy switch studying, outperforming specialised fashions on scientific reasoning benchmarks and sustaining aggressive efficiency on normal alignment duties.
Understanding the Mechanisms
Evaluation of the skilled mannequin reveals fascinating behavioral patterns. Excessive-entropy tokens in reasoning traces fall into two classes: conventional “forking tokens” that set off self-reflection and exploration, and a brand new class of “reflection tokens” that emerge particularly in response to software suggestions.
These reflection tokens characterize a type of environment-driven reasoning the place the mannequin rigorously analyzes code execution outcomes, diagnoses errors, and adjusts its strategy accordingly. This creates extra refined problem-solving habits than pure CoT reasoning can obtain.
Abstract
rStar2-Agent demonstrates that moderate-sized fashions can obtain frontier-level reasoning via refined coaching moderately than brute-force scaling. The strategy suggests a extra sustainable path towards superior AI capabilities—one which emphasizes effectivity, software integration, and sensible coaching methods over uncooked computational energy.
The success of this agentic strategy additionally factors towards future AI techniques that may seamlessly combine a number of instruments and environments, transferring past static textual content era towards dynamic, interactive problem-solving capabilities.
Try the Paper and GitHub Web page. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.