

{kind=link}
Preclinical drug discovery is inherently advanced and data-intensive.
Researchers face the numerous problem of effectively accessing and
analyzing huge volumes of knowledge generated throughout this crucial section.
Conventional keyword-based search strategies, usually reliant on inflexible Boolean
logic, incessantly fall brief when confronted with the nuanced and complex
nature of preclinical analysis questions.
The appearance of Giant Language Fashions (LLMs) has introduced a transformative alternative. By
combining the generative energy of LLMs with the precision of knowledge retrieval programs, Retrieval-Augmented Technology (RAG) has emerged as a promising method.
This strategy holds the potential to revolutionize preclinical information entry, enabling
researchers to pose advanced questions in pure language and obtain correct, context-rich
solutions grounded in proprietary information.
Recognizing this potential early, Bayer dedicated to exploring how these
applied sciences may handle longstanding challenges in preclinical analysis.
On this submit, we share that journey—how Bayer’s early funding in generative AI
has resulted in PRINCE, an agentic AI system constructed on Agentic RAG. This case research
explores the technical structure, engineering selections, and classes
realized in reworking preclinical information retrieval from a difficult maze
into an intuitive conversational expertise.
Lots of the engineering selections behind PRINCE can now be understood by way of the lens of context
engineering and harness engineering, though when the system was first designed we didn’t use these phrases. Context engineering formed what info every mannequin
obtained, what it didn’t obtain, and the way context moved between specialised steps corresponding to
analysis, reflection, and writing. Harness engineering formed the scaffolding across the
fashions: orchestration, instrument boundaries, state persistence, retries, fallbacks, validation,
reflection loops, observability, and human overview.
Whereas this submit focuses on the technical structure and engineering challenges, our paper
revealed in Frontiers in Synthetic Intelligence covers the
product evolution and enterprise affect in additional element.
The Answer: PRINCE – An Evolutionary Platform
To deal with these challenges, Bayer developed the Preclinical
Data Heart (PRINCE) platform. PRINCE was conceived as a unified
gateway to preclinical information, initially specializing in consolidating
beforehand siloed structured research metadata and exposing them in a “Searchable” method.
This preliminary section allowed customers to use superior filters and retrieve
info primarily from structured research metadata.
Nevertheless, a good portion of Bayer’s helpful preclinical
data resides inside unstructured PDF research reviews amassed over
a long time. As a result of quite a few system migrations over time, the structured
metadata related to these reviews may very well be incomplete, lacking, or
even include incorrect annotations. Crucially, the authoritative “gold
normal” info was persistently current throughout the accepted PDF
research reviews.
The emergence of Generative AI, notably RAG, offered the important thing to
unlocking this wealth of unstructured information. By integrating RAG
capabilities, PRINCE started to shift the paradigm from a filter-based
‘search’ instrument to a pure language ‘ask’ system, enabling researchers to
question the content material of those research reviews straight.
This evolution displays PRINCE’s development by way of three distinct
phases:
- Search: the preliminary section centered on making a unified gateway to
1000’s of nonclinical research reviews, consolidating a number of in-house information silos from
numerous preclinical domains right into a
searchable format, primarily leveraging structured metadata. - Ask: this section launched an AI-powered question-answering system using
Retrieval Augmented Technology (RAG). This enabled researchers to derive insights straight
from unstructured information, together with scanned PDFs from historic reviews, by posing
questions in pure language. - Do: the present section positions PRINCE as an lively analysis assistant able to
executing advanced duties. That is achieved by way of the combination of multi-agent programs,
permitting the platform to deal with intricate queries, orchestrate workflows, and assist
actions like drafting regulatory paperwork.
This deliberate evolution from Search to Ask to Do represents a strategic
response to the trade’s want for higher effectivity and innovation in
preclinical growth. By offering researchers with more and more highly effective
instruments to entry, analyze, and act upon preclinical information, PRINCE goals to allow
quicker data-driven decision-making, scale back the necessity for pointless experiments,
and finally speed up the event of safer, more practical
therapies.
System Structure: Engineering a Dependable Agentic RAG System
The system capabilities as an interactive conversational UI, powered by a sturdy backend
infrastructure. Its structure, designed for dealing with advanced queries and delivering
correct, context-rich solutions, is orchestrated utilizing LangGraph and served by way of a
FastAPI software.
Determine 1 supplies the system context—UI, backend, information
shops, LLM fallbacks, and observability—whereas Determine 2
zooms into how the system coordinates its specialised brokers.
{kind=link}
{kind=link}

Determine 1: System context and supporting
platforms.
- Consumer Request: the method begins when a person submits a request by way of the
Conversational UI which is constructed with React. - Orchestration: the person’s request is routed to a LangGraph-based orchestration layer in
the backend. This workflow engine coordinates a multi-stage course of that progresses
by way of
clarifying person intent, pondering and planning, conducting analysis (utilizing RAG and
Textual content-to-SQL),
validating information completion, and at last producing a response by way of the Author agent.
The
workflow contains deliberate pause factors and suggestions loops to make sure information completeness
earlier than
continuing. (We discover the main points of this agentic workflow in a devoted part
later.) - Knowledge Retrieval and State Administration: the Researcher brokers work together with a complete
and
distributed information ecosystem: - Vector representations of all research reviews are saved in OpenSearch, forming
the core data base for info retrieval. - Curated structured information, ensuing from numerous ETL and harmonization
processes, is accessed by way of Athena. - The state of the agent’s execution is meticulously tracked. After every logical
step (a LangGraph node execution), the corresponding state is continued in
PostgreSQL utilizing a LangGraph checkpointer. - Broader application-level state is managed in
DynamoDB. - The system leverages inside GenAI platforms that host fashions from OpenAI, Anthropic,
Google, and open-source suppliers. These platforms expose all fashions by way of a unified
OpenAI-compatible endpoint, making it simple to swap fashions and select the very best instrument for
every process. Additionally they handle the management aircraft, implementing fee limits and different safeguards
to forestall abuse. - Resilience and Error Dealing with: robustness is a crucial design precept, with
a number of fallback mechanisms in place: - If a particular LLM fails, the system mechanically retries
the request a number of instances earlier than falling again to an alternate mannequin or platform to
guarantee service continuity. - To get better shortly from transient failures, retries are
carried out at each the person LLM name degree and the logical node degree (i.e., an
complete step within the agent’s plan). - Additionally, brokers are offered the context of the errors in order that they’ll chart a unique
trajectory or different plan of motion as a response. - Observability and Analysis: your entire system is monitored for efficiency and
reliability: - Basic system well being and metrics are tracked utilizing Cloudwatch.
- Langfuse serves as the first observability instrument, offering detailed traces of
all manufacturing site visitors. This enables for in-depth debugging of points. Moreover,
analysis datasets are saved and managed inside Langfuse, making it simpler to investigate
efficiency scores and diagnose particular failures. The analysis is finished utilizing RAGAS
analysis framework. The stay site visitors analysis is finished every day whereas the
dataset analysis is finished every time important adjustments are made to the core workflow,
prompts, or underlying fashions. - Closing Response: as soon as the brokers have processed the request and generated a
passable response, it’s despatched again to the Conversational UI to be introduced to the
person.
A design precept operating by way of this structure is context self-discipline. Bigger context
home windows didn’t take away the have to be selective about what every agent sees. In early
iterations, placing an excessive amount of info into the context made the system tougher to steer
and tougher to judge. PRINCE due to this fact avoids treating the immediate as one giant container
for all out there info. As an alternative, totally different levels obtain totally different context: planning
context for Assume & Plan, retrieval context for the Researcher Agent, proof context
for the Reflection Agent, and synthesis context for the Author Agent. This reduces context
air pollution and makes the system simpler to debug, consider, and enhance.
These steps be sure that the system can present dependable and contextually related solutions
to a variety of advanced queries by leveraging a complicated, multi-agent structure
and a various set of highly effective instruments and information sources.
The Agentic RAG System
PRINCE incorporates an agentic RAG system (Determine 2) to deal with advanced person requests that require a number of
steps, reasoning, and interplay with totally different instruments or information sources. This setup,
carried out utilizing LangGraph, orchestrates the general workflow and leverages Researcher
Agent, Author Agent, and Reflection Agent for particular duties. The system
is designed to be sturdy and dependable, with a number of fallback mechanisms in place to make sure
that the system can proceed to operate even when a few of the elements fail.
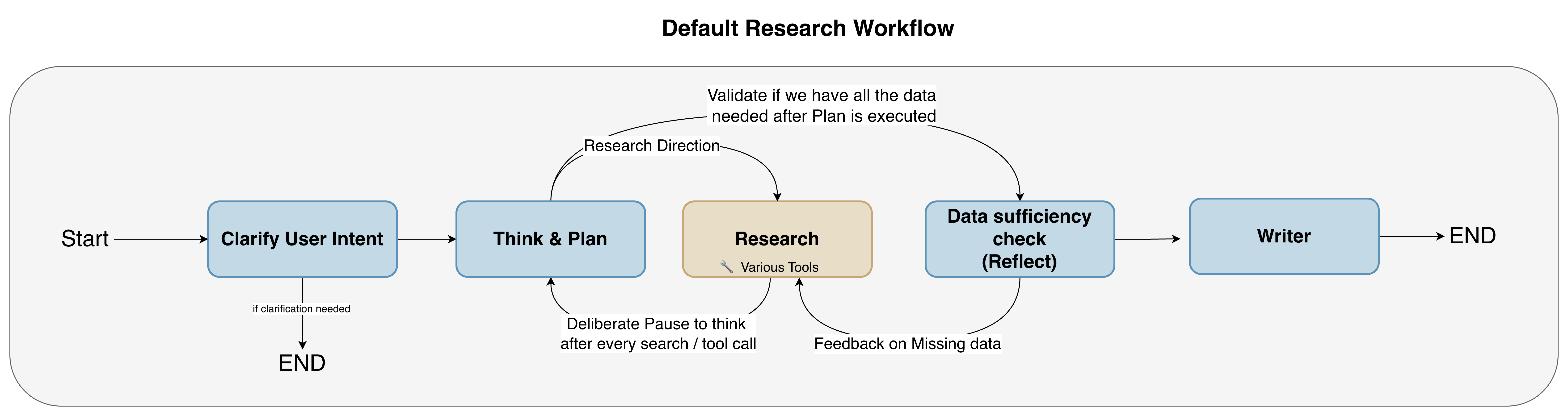
Determine 2: The analysis workflow.
Make clear Consumer Intent
The Make clear Consumer Intent step serves as the primary line of protection towards
ambiguity. Because the system scaled to incorporate numerous domains like toxicology and
pharmacology, easy person queries usually turned ambiguous, making it troublesome to
mechanically choose the precise instruments. Relatively than counting on costly trial-and-error
throughout all information sources, the system proactively asks clarifying inquiries to pinpoint the
particular area or information kind.
This ensures the system enhances the question with the mandatory constraints to focus on the
appropriate instruments. We’re additionally optimizing this by creating domain-level choice in
the UI, which can enable customers to pre-filter legitimate instruments upfront. To additional scale back
friction, the system additionally supplies AI-assisted supply suggestions: when a person has not
chosen any information supply — or has chosen a number of with out a clear focus — the mannequin
analyzes the intent behind the person’s question and suggests essentially the most related sources. The
person retains full management and may settle for, alter, or override the advice, guaranteeing
area experience at all times has the ultimate say. This “fail-fast” mechanism prevents wasted
execution on imprecise queries, whereas cautious tuning ensures the system stays unobtrusive
when the intent is already clear.
From a context engineering perspective, this step is the primary meeting resolution within the
workflow: it constrains which instruments, domains, and information sources can be in scope earlier than any
retrieval begins, guaranteeing subsequent brokers obtain a centered fairly than open-ended
drawback.
Assume & Plan: Course of Reflection
The Assume & Plan step is liable for devising a technique to satisfy the
person’s request. This crucial part provides the system a devoted house to purpose about
the subsequent steps earlier than taking motion—a way impressed by Anthropic’s Assume instrument.
Importantly, this step performs course of reflection: evaluating whether or not the agent is
making the precise progress towards its finish aim and is on proper trajectory, fairly than
evaluating the information itself.
In multi-step agentic workflows, notably these involving many sequential actions,
course of reflection is crucial. Contemplate a situation the place the system must execute 50
steps to finish a fancy process. At every juncture, the system should ask: Am I taking these
steps in the precise method? Am I making the progress I am purported to make? Is the present
trajectory main towards the person’s aim? The Assume & Plan step supplies this
metacognitive functionality, permitting the system to replicate by itself workflow and alter
its technique accordingly.
This “pondering house” has confirmed notably helpful in situations involving a number of
instrument calls.
When PRINCE was initially developed, it had solely a few instruments: one for RAG-based
retrieval and
one other for Textual content-to-SQL queries. Nevertheless, as we built-in extra information sources to broaden the
system’s
capabilities, the variety of out there instruments grew considerably. With this explosion of
instruments got here an
inherent problem: overlapping considerations and area boundaries throughout totally different instruments.
For instance, a number of instruments would possibly serve related however subtly totally different functions—querying
structured
metadata versus unstructured reviews, or retrieving research summaries versus detailed
experimental information.
When introduced with instruments that belong to related domains however deal with barely totally different
information, the LLM
would typically battle to pick out essentially the most applicable instrument for a given question. By
introducing a
devoted pondering step, the system can explicitly purpose about which instrument greatest matches
the person’s
intent, consider the traits of every out there instrument, and make a extra knowledgeable
resolution. This
strategy led to a dramatic enchancment within the accuracy of instrument choice.
Past instrument choice, the Assume & Plan step is crucial for orchestrating
multi-step processes. Many advanced queries in PRINCE require a sequence of instrument calls the place
the output of 1 instrument have to be analyzed earlier than figuring out the subsequent motion. As an example,
the system would possibly first question structured metadata to establish related research, then use
these research IDs to retrieve detailed info from unstructured reviews, and at last
synthesize the findings. And not using a devoted house for course of reflection, the system
would try to execute these steps linearly with out evaluating whether or not every step is
bringing it nearer to the aim. With the pondering step in place, the system can pause,
assess its progress within the workflow, and intelligently plan the next instrument calls
wanted to finish the person’s request.
The Researcher Agent
The Researcher Agent serves because the system’s major info gatherer. As we
onboard new scientific domains onto PRINCE, we persistently observe that information falls into
two major classes: structured and unstructured. Whereas particular
implementation methods could fluctuate throughout domains — as an example, leveraging Snowflake
Cortex Analyst for pharmacology queries for Textual content-to-SQL versus different extra customized strategies
for toxicology—the basics behind these retrieval methods stay constant.
As PRINCE expands throughout a number of preclinical domains, a single Researcher agent with a
flat instrument listing
turns into more and more exhausting to handle. Many instruments function on related ideas—“research”,
“findings”, “assays”—however level to totally different underlying datasets, schemas, and regulatory
interpretations relying on the area. For instance, when a person refers to “the research”,
the related context may be a repeat‑dose toxicology research, a cardiovascular security
pharmacology bundle, or a specific assay in aggregated mass‑information tables, every with its
personal most well-liked sources of reality.
To keep away from one monolithic agent juggling overlapping instruments and subtly totally different information
contracts, we’re actively evolving the Researcher functionality right into a hierarchy of
area‑particular
sub‑brokers. On this proposed structure, every area agent will personal its personal toolset (for
instance, toxicology RAG + tox
metadata SQL, or pharmacology RAG + assay‑degree SQL) together with tailor-made immediate
directions that encode how that area’s information mannequin works, which tables or indices are
authoritative, and easy methods to interpret key ideas. We anticipate this can preserve
obligations coherent,
scale back unintentional cross‑area leakage, and make it simpler to purpose about and check
retrieval behaviour per area.
To successfully harvest insights from this numerous panorama, the Researcher Agent employs
a hybrid retriever strategy centered on two distinct
patterns:
- Retrieval-Augmented Technology (RAG): for processing unstructured information,
primarily PDF reviews. - Textual content-to-SQL: for querying structured information housed in Amazon Athena.
This dual-strategy permits the system to bridge the hole between narrative scientific
reviews and quantitative experimental information.
On this up to date imaginative and prescient, the highest‑degree Researcher Agent is designed to behave as a
coordinator fairly than a
single all‑realizing part. Given the clarified person intent and any express area
choice from the UI, it’s going to route the question to the suitable area sub‑agent, which
can then
resolve easy methods to mix RAG and Textual content‑to‑SQL inside its personal boundary. This sample goals to
protect the simplicity of “one researcher” from the person’s perspective, whereas internally
permitting every area to evolve its personal instruments, schemas, and retrieval recipes with out
destabilizing the remainder of the system.
Retrieval-Augmented Technology (RAG) for Unstructured Knowledge
Given the huge repository of 1000’s of preclinical research reviews and different
unstructured paperwork, RAG is crucial for extracting related insights by grounding
LLM responses on this particular data base. The RAG pipeline contains a
complete ingestion course of and a complicated
query-time structure.
Ingestion Course of: Preclinical research reviews, principally PDFs spanning a long time and
usually together with scanned paperwork with advanced tables, are first centralized into an S3
information lake and handed by way of an extraction pipeline tuned for this corpus. The extracted
textual content is normalized into structured JSON after which chunked utilizing a technique that preserves
sufficient scientific context whereas conserving chunks environment friendly for retrieval.
Every chunk is enriched with research‑ and part‑degree metadata from Amazon Athena (for
instance research ID, compound, species, route, web page, and dad or mum part), which later
allows exact metadata filtering within the RAG layer. Lastly, these annotated chunks are
embedded and listed in Amazon OpenSearch Service,
forming the vector retailer that backs semantic and metadata‑conscious retrieval over each the
historic corpus and the every day deltas as new or up to date reviews arrive.
Question-Time RAG Pipeline: When a person submits a question, the system initiates a
multi-stage retrieval course of. This pipeline is engineered to successfully retrieve the
most related and reliable info from the vector database to floor the LLM’s
response.
For example this pipeline, think about the instance question: “Had been any of the
following scientific findings noticed in research T123456-2: piloerection, ataxia,
eyes partially closed, and unfastened faeces?”. The system processes this question
by way of the next steps:
- Key phrase Extraction: the person’s pure language question is first analyzed by an
LLM. Via cautious immediate engineering, the mannequin is instructed to extract
key phrases extremely related for key phrase search inside our doc corpus (e.g.,
“piloerection”, “ataxia”, “eyes partially closed”, “unfastened faeces”). - Metadata Filter Technology: concurrently, the LLM generates a
metadata filter primarily based on the question. For instance, a filter eq(study_id, T123456-2) is
extracted to slender the search house. This filter is dynamically generated utilizing
few-shot prompting with numerous permutation and mixture examples offered to the
mannequin, guaranteeing it might deal with numerous filtering requests. - Question Growth: to make sure complete retrieval and account for variations in
phrasing and terminology, question growth (multi
question or question rewrite) is carried out by a smaller, quicker mannequin. This generates n=5
semantically related queries primarily based on the unique query. For the instance question,
this would possibly embrace variations like: - “Medical signs reported in analysis T123456-2, together with goosebumps,
lack of coordination, semi-closed eyelids, or diarrhea.” - “Recorded observations in experiment T123456-2 relating to hair standing on
finish, unsteady motion, eyes not totally open, or watery stools.” - “What had been the scientific observations famous in trial T123456-2,
notably relating to the presence of hair bristling, impaired stability,
partially shut eyes, or comfortable bowel actions.” - Hybrid Retriever: info retrieval from the vector database (Amazon OpenSearch
Service) makes use of a Hybrid Search strategy that mixes metadata filtering,
semantic vector similarity search (kNN), and keyword-based retrieval. This course of is
executed as follows: - Metadata Filtering: the metadata filter generated within the earlier step
(e.g., eq(study_id, T123456-2)) is utilized on to the vector database question.
This pre-filters the search house primarily based on the structured metadata hooked up to the
chunks in the course of the ingestion course of from Amazon Athena, guaranteeing that solely chunks
related to the required research ID (or different related metadata) are thought of.
This considerably reduces the search house from hundreds of thousands of vectors to a extra
manageable vary of tens to a whole bunch, enhancing effectivity and relevance. - Parallel Hybrid Search Execution: for every of the n=5 expanded queries, a
single hybrid search question is executed in parallel towards the filtered Amazon
OpenSearch Service vector database. This question combines each semantic vector
similarity search (kNN) and keyword-based search, leveraging OpenSearch’s
capabilities for environment friendly multi-vector and textual content search. - Weighted Consequence Scoring: inside every particular person hybrid search executed in
parallel, a weighted strategy is utilized to the outcomes. A weight of 0.7 is given to
the semantic search outcomes and 0.3 to the key phrase search outcomes to stability
contextual understanding and exact time period matching. This weighting was decided
by way of experimentation to optimize retrieval effectiveness for our information. - Consequence Aggregation and Preliminary Rating: the outcomes (units of related
chunks with their weighted scores) from all 5 parallel hybrid search executions are
aggregated. Distinctive chunks from all search outcomes are pulled collectively, and their
highest weighted rating throughout the parallel searches is used to find out an preliminary
rating. This step initially retrieves a bigger set of potential context chunks
(ok=~20) primarily based on these aggregated and weighted scores. - Reranking: the preliminary set of retrieved chunks (ok=~20) is then refined utilizing a Rerank step. A cross-encoder mannequin (bge-reranker-large)
evaluates the relevance of every retrieved chunk towards the unique query,
choosing the highest ok=7 most related chunks for use as context for the LLM. This
reranking step is essential for guaranteeing that essentially the most pertinent info, even when
not the best in preliminary semantic similarity or key phrase match, is prioritized for
the ultimate response era. - Closing LLM Immediate Technology: the refined context (ok=7 chunks) is then
mixed with the unique query to type the ultimate LLM immediate. This immediate is
rigorously constructed to information the LLM in producing a centered and correct response
primarily based on the offered context, minimizing the danger of hallucination. - Response Technology with Quotation: a state-of-the-art reasoning mannequin then processes
the ultimate
immediate and the offered context to generate response with quotation. The LLM
synthesizes the knowledge from the context to formulate a coherent and correct
reply. Crucially, the response mechanically contains citations linking again to the
particular chunks within the unique doc(s) that assist the generated reply. - Monitoring: your entire Question-Time RAG course of, from preliminary question to last
response era, is constantly monitored utilizing Langfuse for
observability, efficiency and high quality evaluation.
Textual content-to-SQL for Structured Knowledge
Whereas RAG excels at unstructured information, queries requiring exact filtering,
aggregation, or comparability of structured information factors are higher suited to Textual content-to-SQL.
Examples embrace “Give me 50 instance research achieved on RAT” or retrieving particular
numerical assay outcomes together with dosage teams. As proven within the
Researcher Agent can intelligently resolve at hand over such queries to the
Textual content-to-SQL instrument.
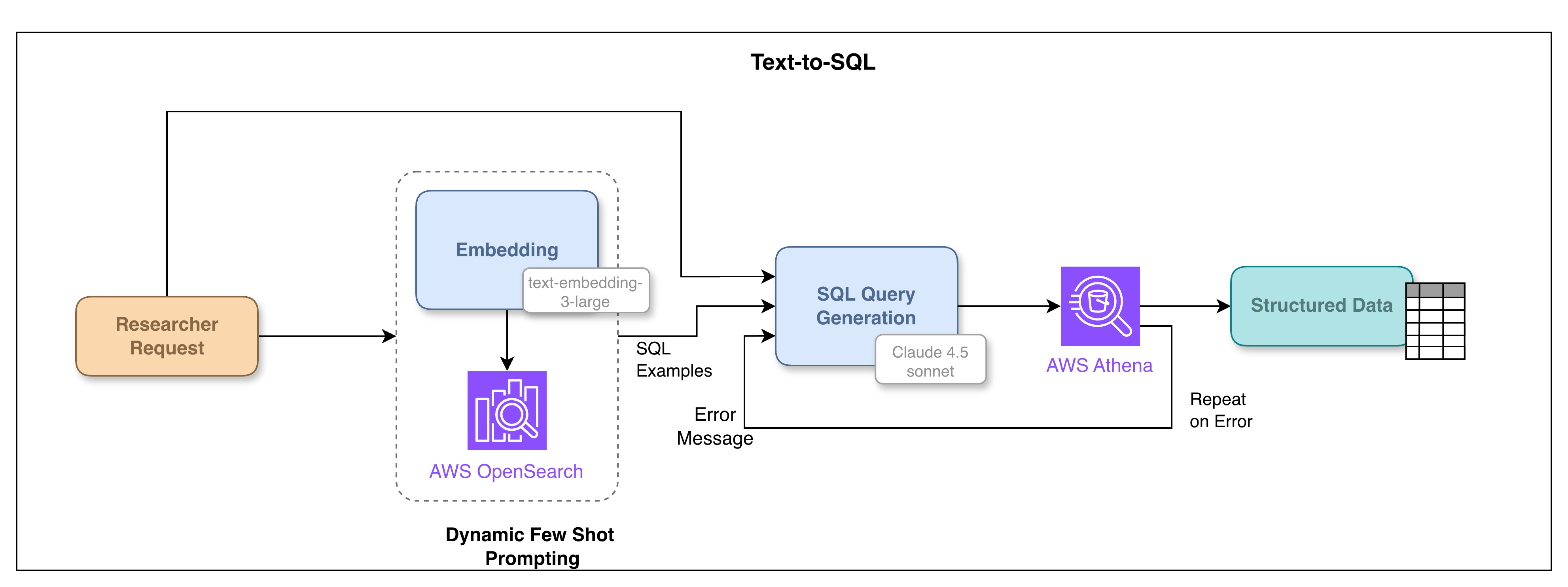
Determine 3: Textual content-to-SQL instrument
The method for changing a pure language query into an executable
SQL question and retrieving outcomes includes a number of key steps:
- Question Evaluation and Intent Recognition: the person’s pure language question is
analyzed to grasp the person’s intent and establish the precise information factors and
filters being requested from the structured metadata. - Schema Understanding and Related Schema Choice: to precisely generate a
SQL question, the LLM requires an understanding of the related database schema. For
giant and sophisticated schemas, solely the mandatory schema elements related to the person’s
question are dynamically injected into the LLM’s context. This reduces the complexity for
the mannequin and improves the accuracy of the generated SQL. - Dynamic Few-Shot Prompting for SQL Technology: changing advanced pure
language queries into exact SQL dialect (in our case, Athena) may be difficult for
LLMs. To deal with this, we make use of dynamic few-shot prompting. A set of rigorously
hand-picked examples, representing numerous advanced question patterns and their
corresponding appropriate SQL translations within the Athena dialect, is saved in a separate
assortment inside our vector database. Primarily based on the person’s question, related examples
are retrieved from this “semantic layer” utilizing vector similarity search and included
within the immediate to the LLM. This supplies the LLM with in-context studying examples,
guiding it to generate correct SQL queries within the appropriate dialect. Steady
addition of latest examples primarily based on encountered challenges additional improves the system’s
efficiency over time. - SQL Question Technology and Validation: a mannequin with robust code era
capabilities,
conditioned on the related schema info and dynamic few-shot examples,
generates the
corresponding SQL question. To make sure the LLM can precisely course of the outcomes and
establish the proper rows for subsequent synthesis, sure important columns, corresponding to
research ID and research title, are at all times included within the generated SELECT question. The
generated question is then validated to make sure it adheres to allowed operations (e.g.,
solely SELECT queries are permitted; DELETE, INSERT, or UPDATE queries are explicitly
blocked for information integrity and safety). Notably, an earlier iteration of this
course of included an LLM overview step for generated SQL queries; nevertheless, this step was
later eliminated because it was discovered that the reviewing LLM typically incorrectly flagged
legitimate queries as inaccurate, hindering effectivity with out a commensurate acquire in
accuracy. - Question Execution and Consequence Limiting: the validated SQL question is executed
towards the structured metadata database in Amazon Athena. To stop information flooding
and handle response dimension, the system enforces a restrict, fetching no more than 50
data at a time. - Error Dealing with and Iteration: if the SQL question execution is profitable, the
retrieved outcomes (as much as the required restrict) are returned and built-in into the
general response era course of. If the question fails as a consequence of syntax errors, schema
points, or different execution errors, the error message from the database, together with the
generated question and the unique context, is handed again to the identical mannequin.
The LLM analyzes the error and the context to generate a corrected SQL question.
This iterative technique of producing and executing SQL queries is tried as much as 3
instances earlier than the instrument provides up and reviews a failure, doubtlessly indicating an
unresolvable question or a limitation within the mannequin’s means to deal with the precise
request.
The Reflection Agent: Knowledge Validation and Sufficiency
Whereas the Assume & Plan step supplies course of reflection, the Reflection
Agent performs a complementary however distinct kind of reflection: information reflection.
This significant part evaluates whether or not the information retrieved from numerous instruments is
adequate and related to reply the person’s query—a basically totally different concern
from whether or not the workflow itself is progressing accurately.
In multi-step agentic workflows, these two forms of reflection serve totally different however
equally vital
functions. Course of reflection (Assume & Plan) ensures the agent is taking the precise
steps and making
applicable progress towards the aim. Knowledge reflection (Reflection Agent) ensures that the
info
gathered by way of these steps is ample to satisfy the person’s request. Each are
important: an agent
would possibly execute a superbly legitimate workflow (good course of) however nonetheless retrieve inadequate
information to reply
the query, or conversely, might need entry to adequate information however fail to progress
successfully
by way of the workflow.
As illustrated within the analysis workflow diagram (Determine 2), after preliminary info retrieval and ‘suppose
& plan’ loops, the Reflection Agent is invoked when Assume & Plan step
thinks that the method has progressed properly sufficient and is able to consider the information.
‘Reflection Agent’ evaluates the sufficiency and relevance of the collected information by
evaluating the retrieved context towards the person’s unique question and figuring out
potential gaps or lacking info. If the gathered info is deemed inadequate
to supply a whole response, the Reflection Agent generates particular follow-up
questions designed to accumulate the mandatory lacking info. These follow-up questions
are then handed again to the Assume & Plan step, which initiates additional
retrieval steps to acquire extra complete outcomes. This iterative course of of knowledge
validation and subsequent info retrieval, pushed by the Reflection Agent‘s
generated questions, demonstrates the system’s means to refine its search technique primarily based
on the preliminary outcomes. If the knowledge is adequate, the workflow proceeds to the
subsequent step.
The Author Agent: Reply Synthesis and Formatting
As soon as the Researcher Agent has collected the related proof from RAG and Textual content-to-SQL,
the Author Agent is liable for turning that uncooked materials into the ultimate reply
proven to the person. Its job is to not “uncover” new info, however to synthesize the
retrieved context, respect person directions, and implement PRINCE’s high quality constraints
throughout era.
The Author Agent operates with a couple of non-negotiable guidelines. It should floor each declare in
the provided context and fasten correct citations again to the underlying chunks and research
IDs, since verifiability is crucial in a regulated setting. It’s also accountable
for honoring user-level formatting necessities (for instance, tables, bullet factors, or
particular part constructions) and for aligning with domain-specific reply requirements used
by the preclinical scientists.
For extra advanced responses—corresponding to multi-section summaries or partially stuffed regulatory
templates—the structure helps extending the Author Agent with a brief inside
overview loop. On this sample, the Author would first draft a solution, then a reviewing
step would verify for lacking sections, inconsistent tables, or gaps relative to the
unique query, and should ship focused directions again to the Author to revise
particular components. This design allows a light-weight type of reflection centered on reply
completeness and
presentation, complementing the Reflection Agent’s give attention to information sufficiency
earlier within the workflow. Importantly, all outputs from these regulatory drafting workflows
are supposed for knowledgeable overview; last submissions are authored and accepted by certified
personnel.
This provides PRINCE three complementary reflection loops. Course of reflection checks whether or not
the workflow is on the precise path and helps catch unhealthy trajectory, mistaken instrument alternative, or
poor sequencing. Knowledge reflection checks whether or not the gathered proof is adequate and
helps catch skinny proof, lacking context, or gaps in protection. Draft reflection checks
whether or not the generated output is full and helps catch lacking sections, incomplete
tables, or synthesis gaps.
Collectively, these brokers type a sensible context engineering sample. The system doesn’t
merely preserve including extra info to the immediate. It routes the precise context to the precise
functionality on the proper time: planning context for Assume & Plan, retrieval context for
the Researcher, proof context for the Reflection Agent, and synthesis context for the
Author. This performs out in concrete selections all through the system: the Textual content-to-SQL step
injects solely the schema elements related to the present question fairly than the total
database schema; the Reflection Agent receives the unique query alongside collected
proof to evaluate gaps, not the total workflow historical past; and the Author Agent receives curated
chunks with quotation constraints, not uncooked retrieval output. Transferring from a monolithic agent
to this structured workflow meant every agent may very well be evaluated, debugged, and improved in
isolation.
Constructing Belief in a Manufacturing LLM System
Constructing and sustaining person belief is paramount for the profitable
adoption of any AI system, notably in a crucial setting like
preclinical drug discovery the place selections have important implications. For
a manufacturing LLM software, belief isn’t just about accuracy; it is also
about reliability, transparency, and the power for customers to confirm the
info offered. A number of mechanisms are built-in into PRINCE
to realize this:
Transparency and Explainability
Making certain transparency and explainability is a crucial side of PRINCE’s
design, fostering person belief and enabling verification of the
generated responses. The system incorporates a number of mechanisms to realize
this:
- Intermediate Steps and Transparency: given the iterative nature of the workflow
and the potential time required to generate a last reply, sustaining transparency is
essential. The intermediate steps executed by the system throughout question processing,
info retrieval, and reflection, together with the queries formulated and the instruments
utilized, are exhibited to the person. This supplies visibility into the system’s
reasoning course of and permits customers to comply with the steps taken to reach on the last
reply. Moreover, when related context (chunks) is recognized, hyperlinks to those
supply supplies are introduced on the display screen, permitting customers to see exactly which
info was shortlisted and used to formulate the ultimate response. - Factuality Verification by way of Quotation: the system facilitates person
verification of factuality by way of a sturdy quotation mechanism. The generated reply is
persistently accompanied by citations referencing the unique supply paperwork and
structured metadata. These citations are straight linked to the context exhibited to the
person, enabling them to simply confirm the accuracy of the claims made within the response and
hint the knowledge again to its origin. Customers can hover over any sentence within the
generated response to see the corresponding quotation, which supplies a hyperlink to the
PRINCE and to the supply doc, together with the web page quantity and the precise quote from
the report used to assist that a part of the reply. This granular degree of quotation
considerably enhances the credibility and trustworthiness of the system’s output and
simplifies the human overview course of.
Analysis
Rigorous analysis is key to constructing and sustaining a dependable
LLM software. PRINCE’s efficiency and reliability are assessed
by way of a mixture of two forms of evaluations: Dataset Evaluations and
Dwell Site visitors Evaluations.
- Dataset Evaluations: carried out every time important adjustments are made to the core
workflow, prompts, or underlying fashions, these evaluations make the most of curated datasets with
pre-defined reference solutions, meticulously ready by material consultants and
saved in Langfuse. A customized analysis script processes every query and compares the
generated response towards the reference reply, yielding quantitative metrics corresponding to
Faithfulness (diploma to which the reply is supported by context), Reply
Relevancy (how properly the reply addresses the question), Context Relevancy
(relevance of retrieved chunks), Reply Accuracy (comparability to floor reality),
and Semantic
Similarity with Reference (semantic similarity to reference reply). Given the
agentic nature of the system, making use of applicable analysis metrics at totally different
workflow levels, analogous to a testing pyramid, is essential along with evaluating
general end-to-end efficiency. - Dwell Site visitors Evaluations: carried out every day as a batch job on actual person queries
from the stay setting (with out pre-defined reference solutions), these evaluations
present helpful insights into real-world efficiency. Metrics corresponding to Faithfulness and
Reply Relevancy can nonetheless be assessed. Dwell site visitors evaluations are important for
monitoring system conduct, figuring out potential points like hallucinations in
manufacturing, and understanding efficiency on numerous stay queries.
Monitoring
Steady monitoring of the system’s efficiency and outputs is crucial
for proactive identification and backbone of points in a manufacturing
setting. Utilizing platforms like Langfuse, we constantly monitor
PRINCE to establish potential biases, errors, or areas for enchancment,
guaranteeing the reliability and security of the system’s responses.
Engineering for Resilience: Error Dealing with and Restoration
Given the complexity of the multi-step workflow inherent in PRINCE,
sturdy error dealing with and restoration mechanisms are crucial to make sure
the system’s reliability and supply a seamless person expertise. The system is
engineered to get better gracefully from failures at numerous levels with out
requiring a whole restart of your entire workflow.
Key facets of our error dealing with and restoration strategy embrace:
- State Persistence: the state of your entire workflow graph is persistently saved,
enabling the system to renew execution straight from the failed node. That is achieved by
storing the Agent State, representing the progress of the brokers by way of the
workflow, in Postgres. Different facets of the appliance state, corresponding to logs, intermediate
steps, and citations, are saved in DynamoDB. This separation and persistence of state are
essential for reaching robustness in a stateful agentic system. - Constructed-in Retries: the system is configured with built-in retries at numerous steps
within the workflow. If a specific step encounters a transient failure, the system will
mechanically try to re-execute it a predefined variety of instances earlier than signaling a
extra everlasting error. - Consumer-Initiated Retries: along with automated retries, customers have the choice
to manually retry a failed question by way of the interface. When a person initiates a retry, the
system leverages the continued state to proceed the workflow straight from the purpose of
failure, intelligently skipping the steps that had been efficiently accomplished within the earlier
try. This considerably improves person expertise and saves computational assets. - Framework-Stage Help: the error restoration mechanisms are considerably
supported by the underlying framework, LangGraph, which affords strong built-in capabilities
for managing workflow state and dealing with errors throughout the graph construction. This supplies
a sturdy basis for constructing resilient agentic workflows. - LLM Fallbacks: to reinforce reliability and mitigate points associated to mannequin
availability or efficiency, the system incorporates customized LLM fallback dealing with. If a
name to a major LLM supplier or a particular mannequin fails after a couple of retries, the system
mechanically falls again to an alternate LLM from a unique supplier. This mechanism
is essential for sustaining system availability and responsiveness, particularly as platform
downtimes for exterior companies are exterior of our direct management.
This complete strategy to error dealing with and restoration minimizes the
affect of transient failures, reduces the necessity for customers to restart advanced
queries from scratch, and contributes to price and latency financial savings by avoiding
redundant execution of profitable steps and LLM calls, all of that are
important for a production-ready system.
These mechanisms are harness engineering in observe. The LangGraph workflow acts as
the management layer across the brokers: it defines which part can act, which instruments it might
use, the place the workflow can pause, how failures are retried, how state is continued, and
when the system ought to transfer from analysis to reflection to writing. This harness makes the
system much less opaque and extra dependable than an unconstrained autonomous agent. It provides the
software clear management factors for restoration, inspection, analysis, and human
intervention.
Enhancing Knowledge High quality: Named Entity Recognition and Annotation
The accuracy and completeness of the structured metadata in Amazon Athena
are crucial for the efficiency of the Textual content-to-SQL part and general information
discoverability inside PRINCE. As a result of historic information migrations and diverse
annotation practices throughout totally different laboratories and programs over Bayer’s
intensive operational historical past, the metadata can typically be incomplete,
lacking, or incorrect.
To deal with this problem and constantly improve the standard of the
structured metadata, now we have developed a utility system that employs Named
Entity Recognition (NER) to extract and create correct annotations straight
from the research PDFs. This technique is designed to learn the textual content material of
the preclinical reviews and establish key entities and related info
that must be represented within the structured metadata.
The method includes:
- Processing research PDFs to extract textual content and establish related entities (e.g.,
research IDs, compound names, species, routes of administration, dosage
info, scientific findings, and so forth.). - Producing structured annotations primarily based on the recognized entities and their
relationships throughout the textual content.
We’re actively engaged on integrating this utility system into our information
pipelines to mechanically appropriate and enrich the information throughout the Amazon
Athena database. The system’s efficiency in producing correct annotations
has been evaluated towards curated datasets, demonstrating promising outcomes.
To handle the combination of those annotations into the manufacturing database,
we’re creating an analysis system that gives a confidence rating for
every extracted discipline. Fields with a excessive confidence rating can be
mechanically used to replace the corresponding entries in Amazon Athena.
Fields with decrease confidence scores can be quarantined and flagged for human
overview and intervention, guaranteeing information accuracy whereas leveraging automation.
This strategy goals to constantly enhance the standard of the structured
metadata, making it a extra dependable supply of knowledge for PRINCE
and different downstream functions.
The Journey Continues: Iterative Growth
PRINCE has been out there to end-users since early 2024, with the agentic
integration launched later that 12 months.
This has been essential for gathering real-world suggestions
and driving iterative growth. A key precept guiding our growth
has been the understanding that constructing a production-ready LLM software is
an iterative course of; we do not anticipate options to be completely good
earlier than looking for person suggestions. As an alternative, we prioritize delivering worth
early and constantly refining the system primarily based on real-world utilization.
Within the preliminary levels, our focus was squarely on reaching the specified
accuracy and efficiency for core functionalities, even when it meant incurring
increased prices. We acknowledged that optimizing for price prematurely may
compromise the system’s effectiveness and hinder person adoption. Solely after
reaching the specified degree of accuracy and efficiency did we start to focus
on price optimization, guaranteeing that effectivity positive aspects didn’t negatively affect
the person expertise or the standard of the outcomes.
The event of PRINCE follows a steady, iterative
course of. Consumer suggestions, ongoing monitoring information, and insights from knowledgeable
scientists are constantly fed again into the event cycle, resulting in
refinements within the structure, retrieval methods, agent behaviors, and
person interface to reinforce efficiency, usability, and finally, scientific
affect.
Conclusion
Constructing a production-ready LLM software in a fancy enterprise
setting like preclinical drug discovery is a journey marked by important
technical and engineering challenges. The PRINCE case research
demonstrates that by combining sturdy information infrastructure, refined
info retrieval methods like RAG and Textual content-to-SQL, and an clever
multi-agent orchestration system, it’s attainable to unlock helpful insights
from huge, beforehand inaccessible information repositories.
Our expertise highlights the crucial significance of specializing in
engineering for reliability, together with sturdy error dealing with, state
persistence, and LLM fallbacks. Moreover, constructing person belief is paramount,
achieved by way of transparency within the workflow, clear explainability by way of
granular citations, and steady analysis and monitoring of the system’s
efficiency.
PRINCE has already proven promising ends in enhancing information
accessibility and analysis effectivity at Bayer, reworking how scientists
work together with preclinical info. This isn’t the top of the journey, however
fairly a major step in the direction of creating actually clever analysis
assistants.
The broader lesson from PRINCE is that production-ready agentic AI just isn’t solely about higher
fashions or higher prompts. Reliability comes from engineering each the context the mannequin sees
and the harness inside which the mannequin acts. Context engineering helped be sure that every
mannequin had the precise info, and solely the precise info, on the proper stage of the
workflow. Harness engineering helped be sure that the workflow remained bounded, observable,
recoverable, and appropriate for a regulated analysis setting.
As mannequin capabilities enhance, some components of at present’s harness could grow to be thinner or transfer
into native mannequin capabilities. However in enterprise analysis programs, particularly the place belief,
traceability, and reviewability matter, express management over context, workflow state,
restoration, reflection, and verification stays important.
We hope this overview supplies helpful insights into the sensible
concerns and technical depth required to construct and productionise LLM
functions in a regulated and data-rich area.