

{kind=link}
Cohere simply launched Command A+, as an open-source mannequin concentrating on enterprise agentic workflows. Accessible underneath an Apache 2.0 license, Command A+ is a mixture-of-experts (MoE) mannequin constructed for high-performance agentic duties with minimal compute overhead. The mannequin is optimized for reasoning, agentic workflows, RAG, multilingual, and multimodal doc processing. It unifies capabilities from 4 prior fashions — Command A, Command A Reasoning, Command A Imaginative and prescient, and Command A Translate — right into a single scalable mannequin.
Structure
Command A+ is a decoder-only Sparse Combination-of-Specialists Transformer with 218B complete parameters and 25B lively parameters. It has 128 consultants, of which 8 are lively per token, and a single shared professional is utilized to all tokens. In a MoE mannequin, every token is routed by solely a subset of professional sub-networks reasonably than the complete parameter set, protecting lively compute at 25B-parameter scale at inference time.
The eye layers interleave sliding-window consideration layers with Rotational Positional Embeddings and world consideration layers with out positional embeddings in a 3:1 ratio. The sparse MoE layer is educated in a completely dropless method and makes use of a token-choice router, with a normalized sigmoid over the top-k professional logits per token.
Enter modalities are textual content, picture, and gear use. Output modalities are textual content, reasoning, and gear use. The mannequin helps a 128K enter context size and a 64K max technology size.
{Hardware} Necessities and Quantization
Three quantization variants can be found with minimal GPU necessities: BF16 (16-bit) requires 4× B200 or 8× H100 GPUs; FP8 (8-bit) requires 2× B200 or 4× H100 GPUs; W4A4 (4-bit) runs on a single B200 or 2× H100 GPUs. All three quantizations present negligible variations in benchmark high quality. Cohere recommends W4A4 for many deployments.
W4A4 Quantization Methodology
Cohere applies NVFP4 W4A4 quantization, 4-bit weights and activations with two-level scaling, to the MoE consultants solely. The eye path, together with Q/Okay/V/O projections, the KV cache, and a focus compute, is saved at full precision.
To shut residual high quality gaps, Cohere makes use of Quantization-Conscious Distillation (QAD) within the post-training section: the quantized pupil mannequin is educated to match the full-precision trainer’s output distribution, utilizing faux quantization operators within the ahead move and straight-through estimators on the backward move.
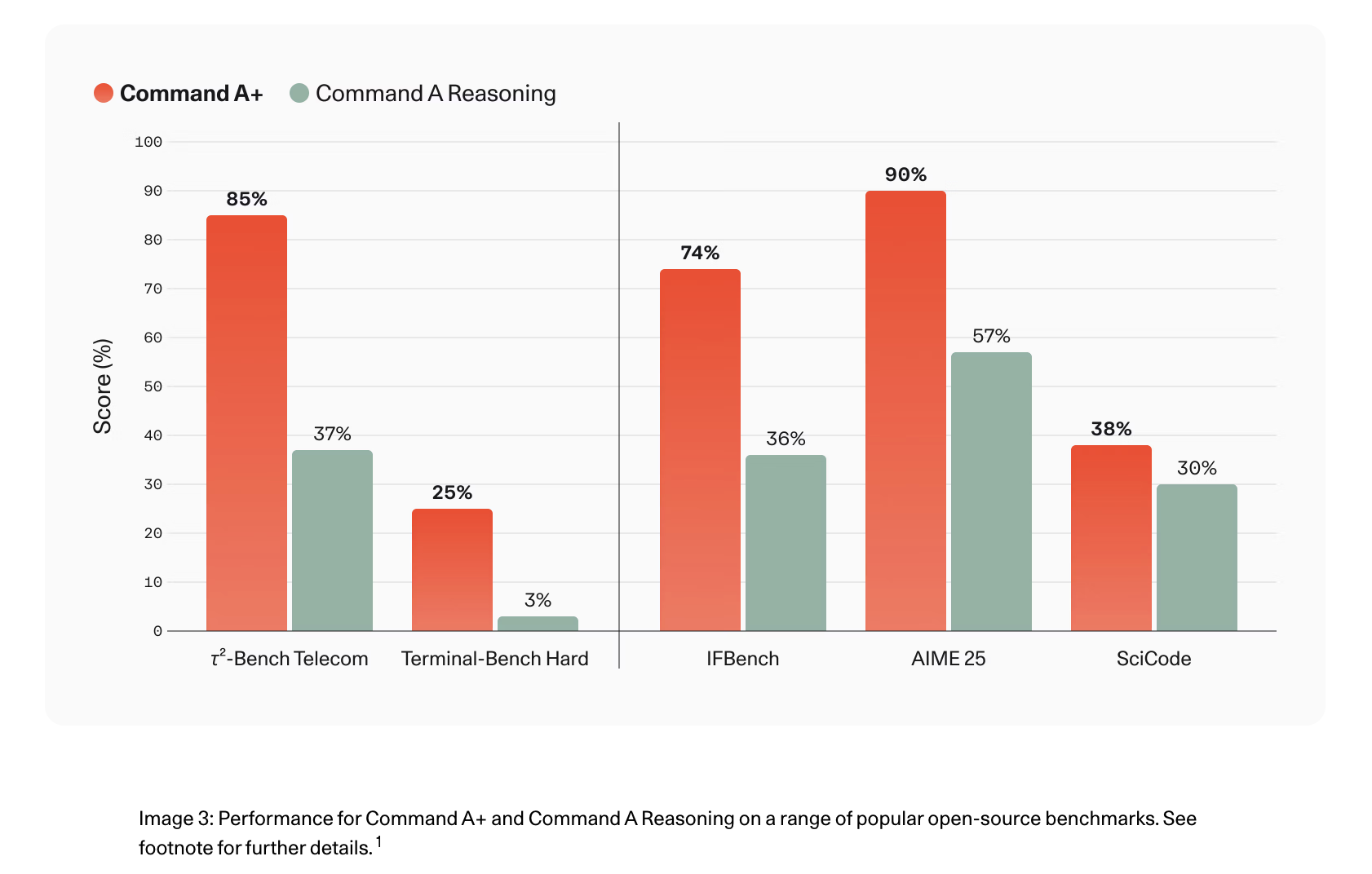
Efficiency vs. Prior Command A Fashions
On τ²-Bench Telecom, scores improved from 37% to 85% over Command A Reasoning, and Terminal-Bench Exhausting agentic coding efficiency reached 25% from 3%.
On inner North platform evaluations, all scored utilizing LLM-as-a-judge methods, Agentic Query Answering accuracy improved by 20% over Command A Reasoning. Agentic QA measures how nicely the mannequin solutions enterprise questions utilizing MCP-connected cloud file methods. Spreadsheet evaluation high quality improved by 32%, and Reminiscence Utilization High quality — measuring how nicely an agent leverages info from a earlier session to reply questions in a subsequent session — scored 54% with Command A+ in comparison with 39% with Command A Reasoning.
Command A+ is Cohere’s first multimodal reasoning mannequin. It achieved 63% on MMMU Professional and 75.1% on MMMU, in contrast with 65.3% for Command A Imaginative and prescient on the latter. MathVista scores improved from 73.5% to 80.6%, and CharXiv reasoning improved from 46.9% to 52.7%.
Command A+ expands multilingual protection from 23 to 48 languages, with features in machine translation and multilingual reasoning.
Command A+ scored 37 on the Synthetic Evaluation Intelligence Index, outperforming different main open fashions.


Velocity and Latency
On the similar quantization and concurrency ranges, Command A+ delivers as much as 63% greater Output Tokens per Second (TOPS) and reduces Time To First Token (TTFT) by as much as 17% in contrast with Command A Reasoning. The W4A4 quantization contributes an extra 47% improve in pace and a 13% discount in latency. Speculative decoding, optimized particularly for the MoE structure, delivers an extra 1.5–1.6× inference speedup for each textual content and multimodal inputs.
Tokenizer
Command A+ is the primary mannequin to make use of Cohere’s newest tokenizer, decreasing the variety of tokens required to generate the identical response. Tokenization effectivity improved by 20% for Arabic, 16% for Korean, and 18% for Japanese.
Getting Began
The mannequin is supported by vLLM and Transformers. Software use is dealt with by chat templates in Transformers utilizing JSON schema for software descriptions. When reasoning is enabled, the mannequin generates pondering traces between <|START_THINKING|> and <|END_THINKING|> tags earlier than producing a ultimate reply.
The W4A4 variant requires vLLM ≥0.21.0 and cohere_melody>=0.9.0 for correct response parsing. Cohere recommends the next sampling parameters: temperature=0.9, top_p=0.95, and repetition_penalty=1.04.
Key Takeaways
- Command A+ has 218B complete / 25B lively parameters in a Sparse MoE structure, launched underneath Apache 2.0.
- W4A4 applies NVFP4 quantization to MoE consultants solely with QAD post-training, working on 2× H100s.
- τ²-Bench Telecom improved from 37% to 85%; Terminal-Bench Exhausting from 3% to 25% vs. Command A Reasoning.
- TOPS elevated as much as 63% and TTFT diminished as much as 17% vs. Command A Reasoning at matching quantization.
- Command A+ is Cohere’s first multimodal reasoning mannequin, increasing language help from 23 to 48 languages.
Take a look at the Mannequin Weights and Technical particulars. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 150k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as nicely.
Have to accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us

Michal Sutter is an information science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.