

{kind=link}
When you have ever stared at hundreds of traces of integration check logs questioning which of the sixteen log recordsdata truly incorporates your bug, you aren’t alone — and Google now has knowledge to show it.
A crew of Google researchers launched Auto-Diagnose, an LLM-powered instrument that mechanically reads the failure logs from a damaged integration check, finds the basis trigger, and posts a concise analysis straight into the code evaluation the place the failure confirmed up. On a guide analysis of 71 real-world failures spanning 39 distinct groups, the instrument accurately recognized the basis trigger 90.14% of the time. It has run on 52,635 distinct failing assessments throughout 224,782 executions on 91,130 code adjustments authored by 22,962 distinct builders, with a ‘Not useful’ charge of simply 5.8% on the suggestions obtained.
The issue: integration assessments are a debugging tax
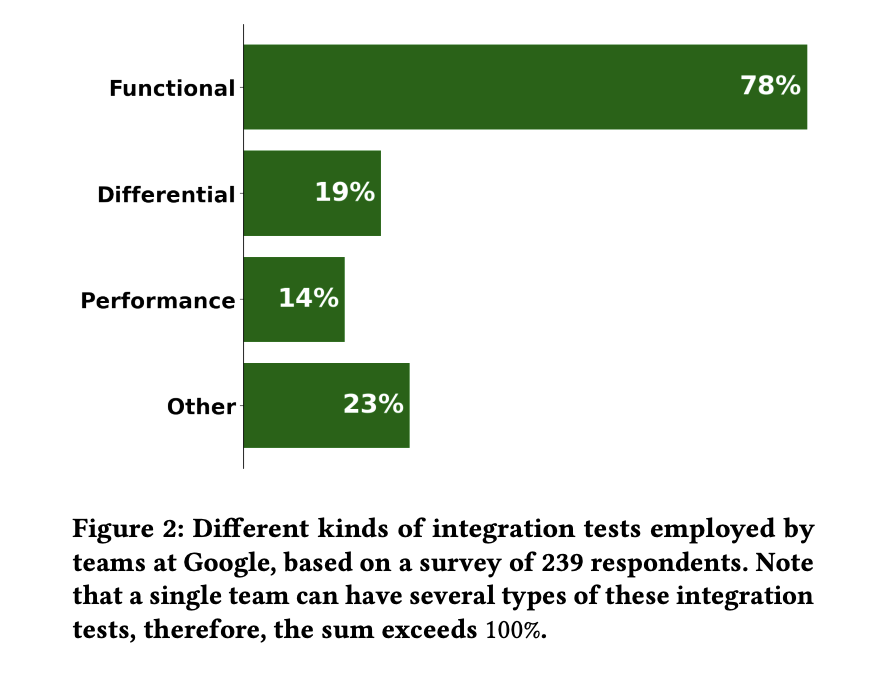
Integration assessments confirm that a number of parts of a distributed system truly talk to one another accurately. The assessments Auto-Diagnose targets are airtight useful integration assessments: assessments the place a complete system beneath check (SUT) — usually a graph of speaking servers — is introduced up inside an remoted setting by a check driver, and exercised in opposition to enterprise logic. A separate Google survey of 239 respondents discovered that 78% of integration assessments at Google are useful, which is what motivated the scope.
Diagnosing integration check failures confirmed up as one of many high 5 complaints in EngSat, a Google-wide survey of 6,059 builders. A follow-up survey of 116 builders discovered that 38.4% of integration check failures take greater than an hour to diagnose, and eight.9% take greater than a day — versus 2.7% and 0% for unit assessments.
The basis trigger is structural. Take a look at driver logs normally floor solely a generic symptom (a timeout, an assertion). The precise error lives someplace inside one of many SUT element logs, typically buried beneath recoverable warnings and ERROR-level traces that aren’t truly the trigger.

How Auto-Diagnose works
When an integration check fails, a pub/sub occasion triggers Auto-Diagnose. The system collects all check driver and SUT element logs at degree INFO and above — throughout knowledge facilities, processes, and threads — then joins and types them by timestamp right into a single log stream. That stream is dropped right into a immediate template together with element metadata.
The mannequin is Gemini 2.5 Flash, referred to as with temperature = 0.1 (for near-deterministic, debuggable outputs) and highp = 0.8. Gemini was not fine-tuned on Google’s integration check knowledge; that is pure immediate engineering on a general-purpose mannequin.
The immediate itself is probably the most instructive a part of this analysis. It walks the mannequin via an express step-by-step protocol: scan log sections, learn element context, find the failure, summarize errors, and solely then try a conclusion. Critically, it contains exhausting unfavorable constraints — for instance: if the logs don’t include traces from the element that failed, don’t draw any conclusion.
The mannequin’s response is post-processed right into a markdown discovering with ==Conclusion==, ==Investigation Steps==, and ==Most Related Log Traces== sections, then posted as a remark in Critique, Google’s inside code evaluation system. Every cited log line is rendered as a clickable hyperlink.
Numbers from manufacturing
Auto-Diagnose averages 110,617 enter tokens and 5,962 output tokens per execution, and posts findings with a p50 latency of 56 seconds and p90 of 346 seconds — quick sufficient that builders see the analysis earlier than they’ve switched contexts.
Critique exposes three suggestions buttons on a discovering: Please repair (utilized by reviewers), Useful, and Not useful (each utilized by authors). Throughout 517 whole suggestions experiences from 437 distinct builders, 436 (84.3%) have been “Please repair” from 370 reviewers — by far the dominant interplay, and an indication that reviewers are actively asking authors to behave on the diagnoses. Amongst dev-side suggestions, the helpfulness ratio (H / (H + N)) is 62.96%, and the “Not useful” charge (N / (PF + H + N)) is 5.8% — nicely beneath Google’s 10% threshold for protecting a instrument dwell. Throughout 370 instruments that submit findings to Critique, Auto-Diagnose ranks #14 in helpfulness, placing it within the high 3.78%.
The guide analysis additionally surfaced a helpful aspect impact. Of the seven circumstances the place Auto-Diagnose failed, 4 have been as a result of check driver logs weren’t correctly saved on crash, and three have been as a result of SUT element logs weren’t saved when the element crashed — each actual infrastructure bugs, reported again to the related groups. In manufacturing, round 20 ‘extra info is required‘ diagnoses have equally helped floor infrastructure points.
Key Takeaways
- Auto-Diagnose hit 90.14% root-cause accuracy on a guide analysis of 71 real-world integration check failures spanning 39 groups at Google, addressing an issue 6,059 builders ranked amongst their high 5 complaints within the EngSat survey.
- The system runs on Gemini 2.5 Flash with no fine-tuning — simply immediate engineering. A pub/sub set off collects logs throughout knowledge facilities and processes, joins them by timestamp, and sends them to the mannequin at temperature 0.1 and highp 0.8.
- The immediate is engineered to refuse somewhat than guess. Arduous unfavorable constraints power the mannequin to reply with “extra info is required” when proof is lacking — a deliberate trade-off that forestalls hallucinated root causes and even helped floor actual infrastructure bugs in Google’s logging pipeline.
- In manufacturing since Could 2025, Auto-Diagnose has run on 52,635 distinct failing assessments throughout 224,782 executions on 91,130 code adjustments from 22,962 builders, posting findings in a p50 of 56 seconds — quick sufficient that engineers see the analysis earlier than switching contexts.
Try the Pre-Print Paper right here. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 130k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as nicely.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us